 |
3. HERITAGE |
L'héritage est certainement l'un des concepts les plus novateurs de la programmation orientée objet. Dans ce chapitre, nous rappelons le concept de polymorphisme dynamique lié à la virtualité et à la redéfinition de méthodes. En outre, le C++ est un langage qui autorise l'héritage multiple, il s'agit d'un concept très souvent critiqué, puisqu'il soulève quelques problèmes d'implémentation. Nous le présentons tout de même, car il peut s'avérer utile dans certaines situations. Nous expliquons alors une alternative à l'héritage multiple, à travers la notion d'interface proposée notamment dans le langage Java.
L'héritage permet de voir un objet comme appartenant à une catégorie plus ou moins précise. Il est donc fondamental de disposer d'un mécanisme, nommé RTTI (Run-Time Type Information) pour le langage C++, qui permet de déterminer la nature exacte d'un objet, notamment au moment de l'exécution du programme. Nous ne l'abordons que très brièvement dans ce chapitre. Enfin, bien que le sujet semble quelque peu éloigné de l'héritage, nous avons choisi de présenter ici les exceptions, un mécanisme qui offre une manière plus élégante de gérer les erreurs dans un programme.
| POLYMORPHISME |
Le terme polymorphisme est employé pour indiquer qu'un élément peut prendre plusieurs formes. Il existe deux types de polymorphisme: le polymorphisme statique et le polymorphisme dynamique. Celui qui nous intéresse ici est le dynamique et concerne plus particulièrement les méthodes. Il signifie que le contenu d'une méthode n'est définitivement établi qu'au moment de son appel. La combinaison de l'héritage, de la virtualité et la possibilité de redéfinir des méthodes permettent ce polymorphisme dynamique.
| Héritage simple |
Avant de s'attaquer au polymorphisme, intéressons-nous simplement à
l'héritage. Une classe permet d'identifier une catégorie de variables dans un
programme, en l'occurrence des objets. L'héritage est un moyen d'organiser ces
catégories. Il permet de définir des catégories générales dans
lesquelles seront réunies des catégories plus précises. Par exemple, la
catégorie (ou classe) Animal peut être précisée (on dit
plutôt spécialisée) en sous-catégories comme
Mammifere, Poisson... En programmation, cette phase de
spécialisation a un intérêt particulier: elle permet de factoriser le code, les
parties communes aux classes Mammifere et Poisson peuvent
être placées dans la classe Animal. Prenons l'exemple suivant où
l'on souhaite positionner sur une carte des animaux identifiés par un nom (e.g. on
établi les bases d'une simulation).
class Animal {
protected:
Chaine _nom; // Nom de l'animal.
int _x; // Abscisse de sa position.
int _y; // Ordonnée de sa position.
public:
Animal(char * n,int x,int y) : _nom(n), _x(x), _y(y) {}
const Chaine & getNom(void) const { return _nom; }
int getX(void) const { return _x; }
int getY(void) const { return _y; }
bool estFemelle(void) const { ... }
};
| Méthode virtuelle, redéfinition et polymorphisme |
La définition précédente de la classe Animal est bien entendue
incomplète. Supposons par exemple que Animal possède les méthodes
deplacer et engendrer, la première déplace l'animal et la
seconde, applicable seulement à une femelle, consiste à mettre bas et donc engendrer
un nouvel Animal. Les poissons et les mammifères ne se déplacent et ne
mettent pas bas de la même manière. Les méthodes sont donc
déclarées dans la classe Animal, puisqu'elles sont communes aux deux
sous-classes. En revanche, le contenu même des méthodes doit être fourni par
chaque sous-classe. Voici les prototypes rajoutés à la classe Animal.
virtual void deplacer(void);
virtual Animal * engendrer(void);
Notez que les deux méthodes sont virtuelles. Cela signifie qu'elles peuvent avoir un
corps mais que les sous-classes sont autorisées à le remplacer (cette action
étant appelée redéfinition). Voici la définition des classes
Poisson et Mammifere.
class Poisson : public Animal {
protected:
int _profondeur; // Profondeur où vit ce genre de poisson.
public:
void deplacer(void) { ... }
Animal * engendrer(void) { if (estFemelle()) { ... } }
};
class Mammifere : public Animal {
protected:
int _vitesse; // Vitesse de déplacement.
public:
void deplacer(void) { ... }
Animal * engendrer(void) { if (estFemelle()) { ... } }
};
Les méthodes redéfinies dans Poisson et Mammifere sont
bien sûr différentes. Notez qu'une fois qu'une méthode est
déclarée virtuelle dans une classe, elle est automatiquement virtuelle dans les
sous-classes, même si le mot-clé virtual n'est pas précisé. Supposons maintenant un
tableau d'animaux, auxquels on applique la méthode deplacer.
int i = 0;
Animal t[] = { Poisson("Maurice",10,20,3),
Mammifere("Rantanplan",5,9,17) };
while (i<n) {
t[i].deplacer();
++i;
}
Si vous vous attendiez à ce que Maurice se déplace comme un poisson et Rantanplan
comme un chien, et bien c'est perdu ! En effet, quand le poisson est placé dans la
première case du tableau, il est converti en un animal (par le constructeur de copie de
cette classe). De la même manière, le mammifère redevient un simple animal dans
le tableau. En résumé, c'est la méthode deplacer de
Animal qui est appelée dans les deux cas. Voici la solution qui fait que chaque
animal se déplace de la bonne manière. Ce qu'on appelle polymorphisme
dynamique, c'est le fait que, au moment de la compilation, on ne sait pas quelle méthode
deplacer va véritablement être appelée, c'est seulement au moment
de l'exécution que tout se décidera.
int i = 0;
Animal * t[] = { new Poisson("Maurice",10,20,3),
new Mammifere("Rantanplan",5,9,17) };
while (i<n) {
t[i]->deplacer();
++i;
}
Il faut savoir que la virtualité d'une méthode l'empêche d'être
déclarée inline, tout simplement parce que le mécanisme d'appel
est différent d'une méthode simple et qu'il ne peut pas être
évité (en effet, c'est à l'exécution qu'on décide
réellement du contenu de la méthode appelée, il est donc impossible à
la compilation de remplacer directement cet appel par un contenu). Et avec les
références, qu'est-ce que ça donne ?
int i = 0;
Animal & t[] = { Poisson("Maurice",10,20,3),
Mammifere("Rantanplan",5,9,17) };
while (i<n) {
t[i].deplacer();
++i;
}
Encore perdu ! On ne peut pas faire un tableau de références. Mais les références permettent le polymorphisme dynamique. Prenons l'exemple suivant.
void deplacer(Animal & a) {
std::cout << "Je deplace " << a.getNom() << std::endl;
a.deplacer();
}
...
int i = 0;
Animal * t[] = { new Poisson("Maurice",10,20,3),
new Mammifere("Rantanplan",5,9,17) };
while (i<n) {
deplacer(*(t[i]));
++i;
}
Dans la fonction deplacer, l'argument reçu est une référence
sur un Animal. Il n'y a donc pas de copie, l'animal est alors soit Maurice, soit
Rantanplan. La nature précise de l'animal sera déterminée seulement à
l'exécution, il y a donc bien polymorphisme dynamique.
| Destructeur virtuel |
Lorsqu'on déclare une méthode virtuelle dans une classe, il faut impérativement que le destructeur soit virtuel. La raison se trouve tout simplement au niveau de la destruction de l'objet. Prenons l'exemple suivant.
Animal * a = new Poisson("Maurice",10,20,3);
...
delete a;
Si le destructeur n'est pas virtuel, alors seul le destructeur de Animal est
appelé. En revanche, s'il est virtuel, le destructeur de Poisson est
également appelé. Mais le mécanisme est à l'image de la construction,
c'est-à-dire que les destructeurs des super-classes sont appelés dans l'ordre inverse
de la construction. Ainsi, pour notre exemple, le destructeur de Poisson est
appelé avant celui de Animal.
| Pointeur de méthode |
De la même manière qu'il existe des pointeurs de fonction en C, il est possible de définir des pointeurs de méthode en C++. Supposons par exemple qu'on souhaite écrire une fonction qui parcourt tous les animaux d'un tableau et appelle une méthode donnée sur chacun des objets.
void parcourir(Animal * t[],int n,void (Animal::*m)(void)) {
int i = 0;
while (i<n) (t[i++]->*m)();
}
L'argument m représente un pointeur de méthode, la seule
différence avec un pointeur de fonction est que le nom de la classe apparaît au moment
de la déclaration du type. Sinon, le format général d'un pointeur de
méthode est très proche de celui d'un pointeur de fonction.
type_retour
(nom_classe::*nom_variable)(type_argument_1,type_argument_2...)
Voici maintenant comment utiliser la fonction parcourir, l'exemple appelle la
méthode deplacer de tous les animaux contenus dans le tableau.
Poisson maurice("Maurice",10,20,3);
Mammifere rantanplan("Rantanplan",5,9,17);
Animal * t[] = { &maurice, &rantanplan };
parcourir(t,2,&Animal::deplacer);
| HERITAGE MULTIPLE |
Est-ce qu'on aurait pas oublié Flipper dans l'histoire ? Oui, je sais, c'est un
mammifère (en particulier il met bas de la même manière), mais avouez
qu'il se déplace plutôt comme un poisson. Donc je propose qu'on déclare une
classe Dauphin qui hérite à la fois de Poisson et de
Mammifere. Attention, notez bien que tous les langages orientés objet
n'autorisent pas cette manipulation. Voici la déclaration de la classe.
class Dauphin : public Poisson, public Mammifere {
...
public:
void deplacer(void) { Poisson::deplacer(); }
Animal * engendrer(void) { return Mammifere::engendrer(); }
};
| Problèmes |
Cette déclaration soulève tout de même quelques problèmes. Tout
d'abord, le dauphin hérite de la méthode deplacer à la fois de
Poisson et de Mammifere. Il faut donc choisir laquelle sera effectivement
appelée quand on voudra déplacer un dauphin. La solution est dans le corps de la
méthode deplacer: celle-ci est redéfinie, et à l'aide de
l'opérateur ::, on appelle la méthode deplacer de la
super-classe qu'on souhaite (ici c'est Poisson).
Le second problème se situe dans la construction même des instances. Revenons aux
classes Poisson et Mammifere, et penchons-nous sur leur constructeur.
Poisson::Poisson(char * n,int x,int y,int p)
: Animal(n,x,y), _profondeur(p) {}
Mammifere::Mammifere(char * n,int x,int y,int v)
: Animal(n,x,y), _vitesse(v) {}
Nous avons vu aux chapitres précédents qu'avant l'appel au constructeur d'une
classe, les attributs étaient construits. En fait, dans le cas d'un héritage, avant
même la construction des attributs, il y a la construction de la partie de l'objet issue des
super-classes. Ainsi, pour les classes Poisson et Mammifere, il faut
construire la partie Animal avant la partie propre à chaque sous-classe. Dans
le cas maintenant de la classe Dauphin, la construction est la suivante.
Dauphin::Dauphin(char * n,int x,int y,int p,int v)
: Poisson(n,x,y,p), Mammifere(n,x,y,v) {}
Le problème de l'héritage multiple devient alors flagrant: une instance
Dauphin se retrouve avec deux fois la partie Animal (l'une issue de
Poisson et l'autre de Mammifere), ce qui n'est pas du tout ce qu'on
souhaite ici.
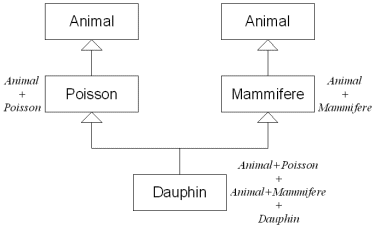
| Héritage virtuel |
Idéalement, il faudrait qu'un dauphin soit constitué d'une seule partie
Animal, d'une sous-partie Poisson et d'une sous-partie
Mammifere. Pour résoudre ce problème, il existe l'héritage
virtuel. L'idée est qu'on hérite d'une classe, mais si par héritage
multiple, on se retrouve avec plusieurs fois la même classe, alors on
ne la considère qu'une seule fois.

Dans notre exemple, il faut donc effectuer les modifications suivantes.
class Poisson : public virtual Animal { ... };
class Mammifere : public virtual Animal { ... };
class Dauphin : public Poisson, public Mammifere {
...
Dauphin(char * n,int x,int y,int p,int v)
: Animal(n,x,y), Poisson(n,x,y,p), Mammifere(n,x,y,v) {}
...
};
Au niveau de la construction, il faut alors détailler le chaînage de la classe de
base (i.e. la super-classe la plus haute dans la hiérarchie) jusqu'aux sous-classes
immédiates. Même si les arguments n, x, y sont
répétés pour le constructeur de Animal, de Poisson
et de Mammifere, ils ne sont réellement pris en compte que dans la classe de
base Animal. Ensuite, ils ne servent qu'à repérer les arguments
significatifs pour chaque sous-classe, i.e. p et v dans notre
exemple.
| CLASSE ABSTRAITE ET INTERFACE |
Nous présentons ici brièvement la notion de classe abstraite, qui peut être associée à la notion d'interface, qui est une alternative intéressante pour l'héritage multiple. Ce concept est notamment proposé dans le langage Java.
| Méthode abstraite |
Une méthode virtuelle peut ne pas avoir de corps. En effet, si l'on reprend l'exemple de
la classe Animal, on peut souhaiter ne pas fournir de comportement par défaut
aux méthodes virtuelles. Une solution peut être de définir les méthodes
de la manière suivante.
virtual void deplacer(void) {}
virtual Animal * engendrer(void) {}
On peut donc créer une instance de la classe Animal qui n'a pas vraiment de
sens, des méthodes sans action pouvant être exécutées.
Il peut être intéressant de définir alors des méthodes virtuelles qui
n'ont pas de corps, ainsi elles ne pourront pas être exécutées directement. Ces
méthodes sont dites abstraites, à l'opposé des autres qui sont dites
concrètes. L'intérêt d'une méthode abstraite est double: elle
empêche tout d'abord la classe d'être instanciée, ensuite elle oblige les
sous-classes à proposer une implémentation.
| Classe abstraite |
Une classe abstraite est tout simplement une classe qui possède au moins une
méthode abstraite. L'exemple suivant rend la classe Animal abstraite, en
déclarant les méthodes virtuelles deplacer et engendrer
abstraites.
virtual void deplacer(void) = 0;
virtual Animal * engendrer(void) = 0;
Les méthodes, comme les fonctions, sont des pointeurs en C++. Pour déclarer une
méthode abstraite, il suffit de lui affecter le pointeur NULL. Lorsqu'une
classe est abstraite, il est impossible de créer une instance de cette classe, seule la
manipulation de pointeurs ou de références est possible. Prenons l'exemple suivant,
toutes les lignes sont autorisées exceptée la première.
Animal a("un animal",0,0);
Poisson p("Maurice",10,20,3);
Animal * pa = &p;
Animal & ra = p;
| Interface et classe abstraite pure |
Une classe abstraite qui ne possède que des méthodes abstraites (aucune méthode concrète, virtuelle ou non, et aucun attribut) est dite abstraite pure. Elle ne décrit en fait qu'une interface, i.e. un jeu de méthodes qu'il faudra implémenter dans les sous-classes si l'on souhaite les instancier. La notion de classe abstraite pure est très proche de la notion d'interface en Java. Ce langage interdit en effet l'héritage multiple de classes concrètes ou abstraites grâce à ce concept.
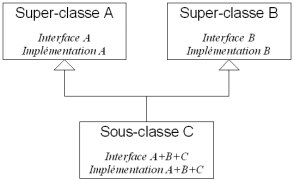
Une classe est formée de deux parties: une interface (qui décrit la partie visible: prototypes des méthodes publiques) et une implémentation (qui décrit la partie cachée: attributs et contenu des méthodes). Lors de la spécialisation d'une classe, son interface et de son implémentation sont héritées toutes les deux, comme le montre la figure suivante.
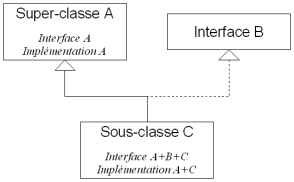
Dans le cas d'un héritage multiple, les problèmes surviennent au niveau de l'héritage des implémentations: méthodes avec le même nom mais un corps différent, ou héritage double d'une classe qui implique une duplication de l'implémentation. Pour éviter ces difficultés, Java empêche l'héritage multiple d'implémentations en imposant l'héritage simple pour les classes et en autorisant l'héritage multiple pour les interfaces.
| MEMBRE DE CLASSE |
Dans tous nos exemples, les attributs que nous avons déclarés sont propres aux
instances, c'est-à-dire que chaque objet construit possède son jeu d'attributs
qu'il est le seul à pouvoir modifier (à condition qu'ils soient encapsulés).
Il est possible de déclarer des attributs propres non pas aux objets mais à la classe
elle-même. Cela signifie qu'il n'existe qu'une seule instance de ces attributs dans tout le
programme et qu'ils sont partagés entre toutes les instances de la classe. Le mot-clé
static est utilisé pour déclarer de tels attributs. Ceux-ci sont
appelés attributs de classe en opposition aux attributs communs dits
d'instance. Dans notre exemple, nous pouvons imaginer un compteur du nombre d'instances de
la classe Animal dans un programme. Pour cela, nous effectuons les modifications
suivantes.
class Animal {
...
protected:
static int _nb_instance;
public:
static int getNbInstance(void) { return _nb_instance; }
Animal(char * n,int x,int y)
: _nom(n), _x(x), _y(y) { ++_nb_instance; }
virtual ~Animal(void) { --_nb_instance; }
...
};
Pour manipuler ces attributs de classe, il est naturellement possible de
créer des méthodes de classe, en utilisant de manière similaire le
mot-clé static. Dans l'exemple, le constructeur et le destructeur sont
utilisés pour mettre à jour le compteur. Ainsi, à tout moment, on
connaît le nombre exact d'instances de la classe Animal dans un programme. Pour
accéder à un membre de classe, on utilise l'opérateur :: de la
manière suivante.
std::cout << "Nombre animaux: " << Animal::getNbInstance();
En résumé, une méthode de classe est équivalente à une fonction, car une instance de la classe n'est pas nécessaire pour appeler l'une de ses méthodes statiques, même si cela reste possible comme le montre le code suivant.
Poisson p("Maurice",10,20,3);
...
std::cout << "Nombre animaux: " << p.getNbInstance();La seule différence avec une fonction est qu'une méthode statique appartient
à sa classe et peut donc accéder à tous ses membres statiques,
cachés ou non. En ce qui concerne les attributs de classe, ils sont aussi
très proches des variables globales, et à leur image, ils doivent être
initialisés dans un fichier source .cpp et non pas dans un header
.hpp (ce qui entraînerait des complications au niveau des inclusions de
fichiers). Ainsi, dans un fichier .hpp, on aura le code suivant.
class Animal {
...
protected: static int _nb_instance;
...
};
Et dans le fichier .cpp associé, on retrouvera le code suivant, qui
initialise l'attribut de classe.
int Animal::_nb_instance = 0;
| MECANISME RTTI |
Le mécanisme RTTI (Run-Time Type Information) est très utile pour
déterminer la classe réelle d'un objet en cours d'exécution, lorsque celui-ci
est pointé ou référencé. Il s'agit du même type de contrôle
que celui effectué par l'opérateur de conversion dynamic_cast. Le
mot-clé typeid est utilisé pour retourner une structure de type
type_info (ne pas oublier d'inclure le fichier <typeinfo>).
Considérons le code suivant.
#include <typeinfo>
...
Poisson p("Maurice",10,20,3);
Mammifere m("Rantanplan",5,9,17);
Animal * pa = &p;
Animal * pb = &m;
...
std::cout << typeid(*pa).name();
La structure type_info contient des informations sur le type fourni à
typeid. Notamment, comme le montre l'exemple, il est possible d'afficher le nom du
type en question. Mais le plus intéressant est que les opérateurs == et
!= ont été surchargés pour le type type_info. Ainsi,
il est possible de vérifier si les pointeurs pa et pb pointent
effectivement sur le même type d'objet.
if (typeid(*pa)==typeid(*pb))
std::cout << "Ils sont de même type.";
else std::cout << "Ils ne sont pas de même type.";
L'opérateur typeid peut également s'appliquer sur un type, ce qui
permet de tester directement qu'un pointeur référence bien, par exemple, un poisson.
if (typeid(*pa)==typeid(Poisson))
std::cout << "C'est un poisson.";
else std::cout << "Ce n'est pas un poisson.";
Il y a tout de même un petit piège avec l'opérateur typeid.
Pour obtenir le type réel d'un objet, il faut fournir sa référence et non pas
son pointeur, comme le montre le tableau ci-dessous. En effet, le pointeur est
considéré comme un type à part et il n'y a donc pas de lien d'héritage
entre deux pointeurs, i.e. un pointeur Poisson * n'a aucun lien (pour
typeid) avec Animal *, alors qu'une référence Animal
& peut en fait être une référence sur un objet de type
Poisson. Considérons le code suivant.
Animal * pp = new Poisson("Maurice",10,20,3);
Animal & rp = *pp;
Le tableau qui suit montre les égalités possibles entre les types, selon qu'il s'agisse de pointeurs ou de références.
typeid(Animal) |
typeid(Poisson) |
typeid(Animal *) |
typeid(Poisson *) |
|
typeid(pp) |
!= |
!= |
== |
!= |
typeid(rp) |
!= |
== |
!= |
!= |
typeid(*pp) |
!= |
== |
!= |
!= |
typeid(&rp) |
!= |
!= |
== |
!= |
| EXCEPTIONS |
Gérer les erreurs dans un programme est toujours une chose très délicate. La technique habituelle consiste à traiter localement le problème, comme dans l'exemple suivant.
void deplacerPoisson(Animal * a) {
Poisson * p = dynamic_cast<Poisson *>(a);
if (p==0) {
std::cerr << "Erreur: ce n'est pas un poisson." << std::endl;
exit(1);
}
... // Le poisson se déplace.
}
Le premier défaut d'une telle approche est de forcer un couplage entre la fonction et la manière d'afficher du programme. En effet, la fonction écrit ici l'erreur sur le flux standard, mais on pourrait imaginer que la fonction est utilisée dans une application graphique où le message d'erreur apparaît dans une boîte de dialogue. Une solution pourrait consister à utiliser une fonction qui se charge d'afficher l'erreur.
void afficherErreur(char * s) {
std::cerr << "Erreur: " << s << std::endl;
exit(1);
}
void deplacerPoisson(Animal * a) {
Poisson * p = dynamic_cast<Poisson *>(a);
if (p==0) afficherErreur("ce n'est pas un poisson.");
... // Le poisson se déplace.
}
L'autre défaut de l'approche est qu'il est difficile dans ce cas de reprendre le programme après le traitement de l'erreur. On a choisit ici de sortir du programme, mais on pourrait imaginer vouloir reprendre le cours du programme à un endroit bien précis. De ces principaux défauts sont nées les exceptions qui permettent une plus grande souplesse et une certaine factorisation dans la gestion des erreurs. Reprenons notre exemple.
void deplacerPoisson(Animal * a) {
Poisson * p = dynamic_cast<Poisson *>(a);
if (p==0) throw Chaine("ce n'est pas un poisson.");
... // Le poisson se déplace.
}
Lorsqu'une erreur est détectée, on choisit de la traiter localement ou de la
transmettre à la méthode (ou à la fonction) appelante. C'est le rôle du
mot-clé throw qui jette un objet, appelé une exception,
à la méthode appelante. Dans l'exemple, throw transmet un objet
Chaine créé à la volée en appelant explicitement son
constructeur. La méthode courante est terminée en détruisant ses
variables locales et ses arguments. Notez que toutes les allocations dynamiques de la
méthode doivent être traitées manuellement. Une fois la méthode
terminée, la main est rendue à la méthode appelante qui suspend alors son
exécution et tente de traiter l'erreur.
int main(void) {
Animal * a = new Mammifere("Rantanplan",5,9,17);
try {
deplacerPoisson(a);
...
}
catch(const Chaine & c) {
std::cerr << "Erreur: " << c << std::endl;
return 1;
}
catch(...) {
std::cerr << "Erreur inconnue." << std::endl;
return 2;
}
return 0;
}
Dans la méthode appelante, une partie de code est surveillée par un bloc
try. Lorsqu'une exception est levée dans cette zone, l'exécution de la
méthode est suspendue et reprend dans l'une des méthodes catch qui suit
le bloc try. Les méthodes sont testées dans leur ordre de
déclaration. Dès que le type de l'argument d'une méthode catch
correspond au type de l'exception levée, alors la méthode est exécutée.
Dans notre exemple, si une exception de type Chaine est levée, alors c'est la
première méthode catch qui est exécutée. En revanche, pour
tous les autres types d'exception, c'est la seconde méthode (qui prend en paramètre
n'importe quel type d'objet grâce au mot-clé ...) qui est lancée.
Notez que pour éviter toute recopie de l'exception, les méthodes catch
reçoivent des références.
Dans l'hypothèse où une méthode m susceptible de recevoir une
exception ne la gère pas (soit parce qu'aucun bloc try n'a été
établi, soit parce qu'aucune méthode catch ne correspond au type de
l'exception) alors l'exception est automatiquement transmise à la méthode qui a
appelé m. Ce processus se répète jusqu'à la fonction
main où l'erreur doit impérativement être traitée. Si ce
n'est pas le cas, l'exception est lancée dans le vide et une erreur du genre aborted
apparaît.
Dans notre exemple, nous avons simplement jeté un objet de type Chaine. Mais
grâce à la STL, le C++ fournit une hiérarchie de classes d'exception. La
classe de base (i.e. la classe en haut de la hiérarchie) est exception. Elle se
décline ensuite en sous-classes pour divers types d'erreur: fichiers, débordement...
(cf. cette page pour les détails). Voici un exemple simple qui permet de
créer sa propre classe d'exception (très important pour éviter de
réécrire le message d'erreur à chaque appel, mais également pour
permettre des traitements différents au niveau des catch, en fonction de la
classe de l'exception).
#include <stdexcept>
class ErreurConversionPoisson : public std::exception {
public:
const char * what(void) const throw()
{ return "ce n'est pas un poisson."; }
};
void deplacerPoisson(Animal * a) {
Poisson * p = dynamic_cast<Poisson *>(a);
if (p==0) throw ErreurConversionPoisson();
... // Le poisson se déplace.
}
int main(void) {
Animal * a = new Mammifere("Rantanplan",5,9,17);
try {
deplacerPoisson(a);
...
}
catch(const std::exception & e) {
std::cerr << "Erreur: " << e.what() << std::endl;
return 1;
}
catch(...) {
std::cerr << "Erreur inconnue." << std::endl;
return 2;
}
return 0;
}
La classe exception implémente une méthode virtuelle
what qui retourne le message associé à l'erreur. Pour créer sa
propre classe d'exception, il suffit de redéfinir cette méthode avec son propre
message (ne pas oublier d'inclure le fichier <stdexcept>). Notez qu'il est tout
à fait possible de rajouter des attributs: par exemple, pour une erreur
d'entrée/sortie, le nom du fichier qui pose problème peut être
mémorisé.
class ErreurFichier : public std::exception {
protected:
Chaine _fichier;
public:
ErreurFichier(char * s) : _fichier(s) {}
const char * what(void) const throw() {
Chaine c = Chaine("impossible d'ouvrir le fichier ")+_fichier;
return (const char *)c;
}
};
...
if (...) throw ErreurFichier("dummy.txt");
...
|