 |
5. LA BIBLIOTHEQUE STL |
La bibliothèque STL (Standard Template Library) fait actuellement partie intégrante du langage C++. Il s'agit d'un ensemble de structures de données (des conteneurs) et d'algorithmes suffisamment performants pour répondre aux besoins usuels des programmeurs. Afin de rendre ces composants génériques, ils sont proposés pour la plupart sous forme de patrons de classe ou de fonction.
Les conteneurs sont des classes génériques et les algorithmes des patrons de fonction. Afin de rendre les conteneurs interchangeables et rendre ainsi l'utilisation d'un algorithme possible sur tous, des objets intermédiaires, nommés itérateurs, sont manipulés. Les algorithmes sont également conçus pour être extensibles, grâce au concept de foncteur. La STL fournit aussi des adapteurs, qui sont des classes permettant l'adaptation d'un conteneur pour lui procurer de nouvelles fonctionnalités.
L'objectif de ce chapitre n'est pas de présenter tous les détails de la bibliothèque, mais simplement de fournir les notions nécessaires à l'utilisateur pour l'exploiter au mieux. En ce qui concerne des documentations complètes, voici quelques liens.
SGI's STL
Documentation et code source de la STL fournie par SGI. Entre autres, l'index est très utile pour accéder rapidement aux fonctionnalités d'un conteneur ou d'un algorithme.STL Quick Reference
Un document concis et précis sur les principales fonctionnalités de la STL. Il s'agit d'un aide-mémoire qui répertorie les prototypes des méthodes des conteneurs et des principaux algorithmes.
Un diagramme UML qui vient compléter le document précédent, il décrit les relations et les principales fonctionnalités des conteneurs de la STL.
| PACKAGE |
| Espace de nommage, namespace |
La STL est fournie sous la forme d'un package, les composants sont rassemblés sous un
même espace de nommage (ou namespace). Cela signifie que pour utiliser un composant,
il faut précéder son nom de l'espace de nommage, en l'occurrence std.
Par exemple, pour utiliser l'algorithme find du package std, il
faut écrire std::find. Pour éviter d'écrire à chaque fois
le nom du package, il est possible de l'intégrer dans l'espace de nommage courant par
la commande suivante.
using namespace std;
Par défaut, l'espace de nommage courant n'a pas de nom, et écrire
find ou ::find est donc équivalent. Mais il est possible de
définir ses propres espaces de nommage.
namespace mon_espace {
using namespace std;
class MaClasse { ... find(...) ... };
}
Dans l'espace de nommage mon_espace, la classe MaClasse est
définie, et le namespace std est intégré à
mon_espace. Cela signifie que de l'extérieur de l'espace de nommage,
std::find et mon_espace::find sont équivalents. En revanche, dans
l'espace de nommage mon_espace, find peut être appelée
directement.
| Inclusions |
Les headers fournis par la STL n'ont pas d'extension. Par exemple, pour utiliser la
fonction std::find, il faut inclure le fichier <algorithm>.
L'espace de nommage std
contient également toutes les fonctions et les types qui font partie du C standard. Par
exemple, la fonction strcpy est devenue std::strcpy. En ce qui concerne
les headers du C standard, leur nom est légèrement changé, l'extension
est retirée et la lettre c est rajoutée en début de nom. Par exemple,
en C, strcpy est déclarée dans <string.h>,
alors qu'en C++, on inclura plutôt le fichier <cstring>.
| CONTENEURS DE SEQUENCE |
La bibliothèque STL propose différents types de conteneur. La première
catégorie regroupe les conteneurs de séquence. Il s'agit de listes
d'éléments dont l'ordre est entièrement contrôlé par
l'utilisateur. Le schéma suivant montre les méthodes communes et les méthodes
spécifiques aux trois types de conteneur de séquence: vector,
deque et list. Une petite remarque
concernant les notations: les classes en italique ne sont pas de véritables classes dans la
STL, il ne s'agit que de classes abstraites utilisées pour montrer l'organisation des
conteneurs. Dans la bibliothèque, les conteneurs sont simplement des classes
génériques sans aucun lien explicite.
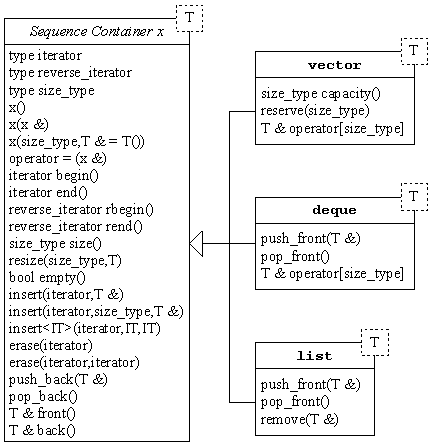
Outre les
méthodes classiques telles que la recopie (par l'intermédiaire du constructeur de
copie et de l'opérateur d'affectation), ces conteneurs proposent l'ajout
(push_back) et la suppression (pop_back) d'un élément en
fin de liste, et l'accès au premier élément (front) et au dernier
élément (back). La méthode size permet de
connaître le nombre d'éléments dans un conteneur, et resize permet
de redimensionner l'ensemble, soit en retirant des éléments (les derniers), soit en
rajoutant des éléments (à la fin) à partir d'un modèle. La
définition d'un conteneur est toujours présente dans le header du même
nom, i.e. pour utiliser vector, il faut inclure le fichier
<vector>.
| vector |
Le but du vecteur est de remplacer le tableau classique. Sa structure interne est un tableau qui est redimensionnable, automatiquement ou manuellement. A tout moment, il est possible d'ajouter un élément, il n'y a pas de limitation (hormis l'espace mémoire). Ainsi, si le tableau interne est plein au moment de l'ajout d'un nouvel élément, alors il est réalloué avec une taille plus importante et tous ses éléments sont recopiés dans le nouvel espace. La règle couramment employée consiste à doubler la taille chaque fois que le tableau est plein.
vector<int> v;
for (int i=0; i<10; ++i) v.push_back(i);
L'efficacité par rapport à un tableau est naturellement moindre, mais elle reste
tout à fait acceptable (perte d'environ 10 %). En outre, il possible de contrôler
à l'avance la taille du tableau interne (grâce à la méthode
reserve), ce qui permet d'éviter la réallocation du tableau. Les
performances sont alors équivalentes à celles d'un tableau.
vector<int> v;
v.reserve(10);
for (int i=0; i<10; ++i) v.push_back(i);
Il est aussi possible d'initialiser un vecteur rempli d'un certain nombre d'éléments. Ces derniers sont créés à partir du constructeur par défaut de leur classe.
vector<int> v(10);
for (int i=0; i<10; ++i) v[i]=i;
Il est possible d'accéder directement à un élément d'un vecteur
à partir de son index, en utilisant l'opérateur [].
La numérotation des éléments débute à zéro, comme pour un
tableau classique.
| deque |
L'intérêt de la deque (double-ended queue) par rapport au vecteur est
de pouvoir ajouter (push_front) ou retirer (pop_back) un
élément en début de liste. La structure interne de ce conteneur est un hybride
entre une pile et une file d'attente. Les performances de la deque sont très bonnes
pour l'ajout et la suppression d'éléments, que ce soit en tête ou en fin de
liste. Elles surpassent même le vecteur au niveau de l'insertion, puisque les défauts
liés à la réallocation sont évités.
| list |
La liste propose également un ajout et une suppression en début de liste. La
structure interne du conteneur est une liste doublement chaînée. Son
intérêt par rapport à la deque réside dans l'ajout et la
suppression en milieu de liste, rendus possibles par l'intermédiaire des itérateurs.
Grâce à la structure de liste chaînée, ces opérations sont
très efficaces. Il existe également des fonctions spécifiques à la classe
générique list telles que slice qui permet de scinder
rapidement la liste.
| ITERATEURS |
Un itérateur est un pointeur, au sens objet, sur un élément d'un conteneur. Il s'agit d'un design pattern introduit par le GoF. En d'autres termes, c'est un objet fourni par un conteneur et qui pointe directement sur sa structure interne. Cela évite de dévoiler la structure interne à l'utilisateur, tout en fournissant un accès efficace aux éléments. Un itérateur sur un conteneur ne peut être créé que par le conteneur même. L'exemple suivant montre comment afficher le contenu d'un vecteur à l'aide d'itérateurs.
vector<int> v;
...
vector<int>::const_iterator courant = v.begin();
vector<int>::const_iterator fin = v.end();
while (courant!=fin) std::cout << *(courant++) << ' ';
Pour obtenir un itérateur, il faut utiliser les méthodes begin et
end du conteneur qui retournent respectivement un itérateur sur le début
de la liste et un itérateur sur l'élément fictif juste après la fin de
la liste. Un itérateur dispose des opérateurs ++ pour avancer au
prochain élément (attention, ne pas utiliser -- pour reculer, ça
ne marche pas toujours), et de l'opérateur * pour accéder à
l'élément pointé. Les opérateurs == et !=
sont également disponibles pour vérifier si deux itérateurs pointent au
même endroit.
Le type des itérateurs est également fourni par le conteneur. Il dispose de types
internes (e.g. iterator, const_iterator, reverse_iterator...) qui
représentent différentes catégories d'itérateurs. Dans l'exemple, nous
avons utilisé const_iterator qui représente un itérateur sans
autorisation de modification de l'élément pointé. Dans l'exemple suivant, nous
utilisons le type iterator, où la modification de l'élément
pointé est autorisée.
vector<int> v;
...
vector<int>::iterator courant = v.end();
vector<int>::iterator fin = v.begin();
while (courant!=fin) *(courant++)*=2;
Dans cet exemple, tous les éléments du conteneur sont multipliés par 2. Un
autre type intéressant d'itérateur, reverse_iterator, permet de
parcourir la liste en sens inverse: rbegin retourne un itérateur sur la fin de
la liste et rend retourne un itérateur sur l'élément fictif juste
avant le début de la liste.
vector<int> v;
...
vector<int>::reverse_iterator courant = v.rbegin();
vector<int>::reverse_iterator fin = v.rend();
while (courant!=fin) std::cout << *(courant++) << ' ';
Mais quel est le véritable intérêt d'un itérateur ? On peut penser que disposer de méthodes de parcours directement dans le conteneur serait suffisant. Mais on peut instancier autant d'itérateurs qu'on souhaite pour un conteneur donné, et initier ainsi plusieurs parcours sur la structure (sans en connaître les détails), ce qui ne serait pas forcément évident si les méthodes d'accès étaient directement fournies par le conteneur. Il est également important de rendre les conteneurs interchangeables. Considérons la fonction suivante qui trie par ordre croissant tous les éléments du vecteur fourni en argument.
template <typename T> void trier(vector<T> & v) {
int i = 0;
int j;
while (i<v.size()) {
j=i+1;
while (j<v.size()) {
if (v[j]<v[i]) std::swap(v[i],v[j]);
++j;
}
++i;
}
}
Ce serait dommage de devoir réécrire cette fonction pour un autre type de conteneur. Donc, au lieu d'utiliser les indices pour accéder aux éléments (ce qui est propre au vecteur et à la deque), nous utilisons des itérateurs.
template <typename T> void trier(vector<T> & v) {
typename vector<T>::iterator fin = v.end();
typename vector<T>::iterator i = v.begin();
typename vector<T>::iterator j;
while (i!=fin) {
j=i;
++j;
while (j!=fin) {
if (*j<*i) std::swap(*i,*j);
++j;
}
++i;
}
}
Vous remarquerez que pour utiliser le type interne iterator de
vector<T>, il est précédé du mot-clé
typename. La raison est simple, lorsqu'on dispose d'un paramètre T
dans un patron, rien ne garantit qu'il possède un membre donné. En ce qui concerne
les attributs et les méthodes, le compilateur fait confiance à l'utilisateur à
la première vérification du template. Il effectuera le véritable test
au moment de l'instanciation du patron. En ce qui concerne les types internes, c'est un peu
différent, le compilateur prévient le programmeur par un message indiquant qu'il ne
connaît pas le type. Ainsi, pour le code T::iterator, le compilateur demande
confirmation par l'ajout du mot-clé typename. Dans le cas de
vector<T>::iterator, le compilateur considère
vector<T> aussi inconnu que T, même si le patron
vector est connu (on ne sait jamais, il est possible à tout moment de
définir une instanciation partielle de vector).
Dans la fonction précédente, il n'existe plus de code propre au vecteur, exceptée l'initialisation des itérateurs de début et de fin qui pourraient être fournis comme argument.
template <typename I>
void trier(const I & debut,const I & fin) {
I i = debut;
I j;
while (i!=fin) {
j=i;
++j;
while (j!=fin) {
if (*j<*i) std::swap(*i,*j);
++j;
}
++i;
}
}
La fonction est alors utilisable pour tout type de conteneur pour lequel il est possible de fournir des itérateurs. Ces derniers ont donc un rôle d'intermédiaires entre un algorithme et le conteneur auquel ils sont associés. Quelque soit leur conteneur, ils implémentent tous la même interface et sont donc totalement interchangeables.
Les itérateurs peuvent également être utilisés pour insérer un
élément en milieu de liste. Les conteneurs de séquence disposent de la
méthode insert qui permet d'insérer un élément à la
position précédant celle pointée par l'itérateur fourni. Ainsi,
v.insert(v.begin(),10) insère l'élément en début de liste
et v.insert(v.end(),10) l'insère en fin de liste.
| ALGORITHMES |
Les algorithmes sont élaborés sur le même modèle que notre dernier
exemple. C'est-à-dire qu'au lieu de passer le conteneur en argument, il faut fournir des
itérateurs pour délimiter la liste d'éléments. Les algorithmes sont des
patrons de fonction dans la STL et sont définis dans le header
<algorithm>. Par exemple, il existe le patron sort qui trie les
éléments d'un conteneur.
std::sort(v.begin(),v.end());
Nous n'allons pas détailler ici tous les algorithmes, nous vous invitons à
consulter la documentation pour plus d'informations. Nous signalons juste la fonction
find, qui recherche dans une liste, identifiée par un iterateur de début
et de fin, un élément donné, et retourne alors comme résultat un
itérateur sur cet élément.
vector<int>::const_iterator i = std::find(v.begin(),v.end(),28);
| FONCTEURS |
Il est possible d'étendre certains algorithmes de la STL. La méthode employée repose sur le concept de foncteur qui est une adaptation d'un design pattern du GoF appelé visiteur. Pour illustrer ce concept, revenons à notre exemple de fonction de tri. Nous souhaitons maintenant pouvoir paramétrer l'ordre du tri. En analysant la fonction, on s'aperçoit que l'ordre est simplement déterminé par le test qui vérifie qu'un élément doit se situer avant un autre. Pour rendre l'algorithme plus générique, il suffit de déporter ce test dans une fonction. Celle-ci sera alors passée en paramètre (i.e. en tant que pointeur de fonction) à la fonction de tri, et pourra alors être remplacée pour changer l'ordre du tri.
template <typename T,typename I>
void trier(const I & debut,const I & fin,
bool (*estAvant)(const T &,const T &)) {
I i = debut;
I j;
while (i!=fin) {
j=i;
++j;
while (j!=fin) {
if (estAvant(*j,*i)) std::swap(*i,*j);
++j;
}
++i;
}
}
Pour définir par exemple un tri croissant, il suffit d'écrire une fonction qui vérifie qu'un élément est inférieur à un autre.
template <typename T>
bool estAvantCroissant(const T & a,const T & b) { return a<b; }
...
trier(v.begin(),v.end(),estAvantCroissant);
Ce genre de fonction peut être considérée comme un objet, c'est ce qu'on
appelle un visiteur. Il s'agit d'un objet qui possède des méthodes
indispensables pour compléter un algorithme, ce qui permet alors d'en modifier son
comportement. Ainsi, la fonction estAvantCroissant peut être remplacée
par la classe OrdreCroissant.
template <typename I,typename O>
void trier(const I & debut,const I & fin,const O & ordre) {
I i = debut;
I j;
while (i!=fin) {
j=i;
++j;
while (j!=fin) {
if (ordre.estAvant(*j,*i)) std::swap(*i,*j);
++j;
}
++i;
}
}
template <typename T> class OrdreCroissant {
public:
bool estAvant(const T & a,const T & b) const { return a<b; }
};
...
trier(v.begin(),v.end(),OrdreCroissant<int>());
Enfin, notamment pour éviter à l'utilisateur de retenir le nom des méthodes des
visiteurs à chaque nouvel algorithme, la STL propose le foncteur qui est un visiteur
possédant l'opérateur (). Ainsi, lorsque la méthode est
appelée, le visiteur ressemble syntaxiquement à une fonction.
template <typename I,typename O>
void trier(const I & debut,const I & fin,const O & estAvant) {
I i = debut;
I j;
while (i!=fin) {
j=;
++j;
while (j!=fin) {
if (estAvant(*j,*i)) std::swap(*i,*j);
++j;
}
++i;
}
}
template <typename T> class OrdreCroissant {
public:
bool operator()(const T & a,const T & b) const { return a<b; }
};
La STL propose une fonction de tri, sort, qui possède le même
prototype que notre dernière fonction trier. Pour trier un vecteur
v dans l'ordre croissant, il suffit d'exécuter le code suivant.
std::sort(v.begin(),v.end(),OrdreCroissant<int>());
Si aucun foncteur n'est passé en paramètre, le foncteur less
(équivalent à OrdreCroissant) est utilisé. En
général, tous les algorithmes et les conteneurs de la STL qui nécessitent un
foncteur pour une relation d'ordre utilisent par défaut less. Ainsi, le
simple code suivant est possible.
std::sort(v.begin(),v.end())
L'intérêt majeur des visiteurs réside dans leur capacité à
posséder leurs propres données, ce qui n'est pas concevable avec des pointeurs
de fonction. Considérons par exemple l'algorithme
generate fourni par la STL. Il parcourt un conteneur (par l'intermédiaire
d'itérateurs) et remplace chaque élément par une valeur fournie par un
foncteur. Supposons qu'on souhaite remplir le conteneur de nombres pairs.
class GenerateurNombrePair {
protected:
int _x;
public:
GenerateurNombrePair(int x) : _x(x/2*2) {}
int operator()(void) {
int y = _x;
_x*=2;
return y;
}
};
...
vector<int> v(10);
std::generate(v.begin(),v.end(),GenerateurNombrePair(8));
L'exemple précédent remplit le vecteur v d'une séquence de
10 nombres pairs, à partir de la valeur 8. L'avantage du visiteur par rapport à
un pointeur de fonction est ici d'avoir une mémoire. En effet, à chaque appel, le
générateur retourne la valeur suivante dans la séquence.
| CONTENEURS TRIES |
La seconde catégorie de conteneurs proposée dans la STL regroupe les structures de
données triées. Le schéma suivant montre les méthodes communes et les
méthodes spécifiques aux deux types de conteneur trié: les ensembles (i.e.
set et multiset) et les conteneurs associatifs (i.e. map et
multimap).
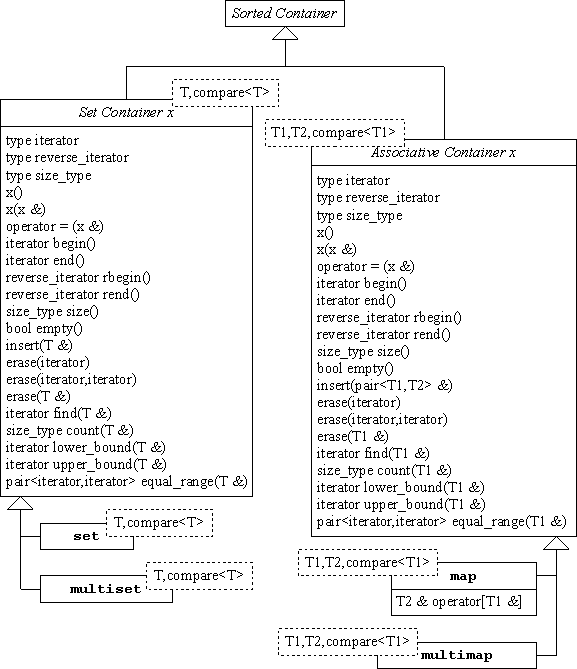
Notez que pour
tous ces conteneurs, il est nécessaire de fournir un foncteur qui permet de trier les
éléments. Par défaut, le foncteur less est utilisé. Les
itérateurs sont bien sûr disponibles pour ces conteneurs.
| Ensembles, set et multiset |
La classe set représente un ensemble trié où les
éléments sont uniques. Pour vérifier que deux éléments sont
différents, il suffit d'utiliser la relation d'ordre fournie par un foncteur
(compare<T> sur le schéma): a!=b si et seulement si
a<b ou b<a. La classe multiset autorise en revanche
les doublons.
Pour ajouter un élément, on utilise la méthode insert qui
garantit, dans le cas d'un set, l'unicité de la valeur. Pour supprimer un
élément, on utilise la méthode erase, en fournissant soit
directement la valeur à retirer, soit un itérateur pointant sur
l'élément à supprimer. Une méthode find est
également disponible pour rechercher un élément, elle retourne un
itérateur sur l'élément. Comme l'ensemble est trié, la recherche
s'effectue relativement rapidement. La structure interne du conteneur est un arbre binaire de
recherche.
| Conteneurs associatifs, map et multimap |
Les classes map et multimap sont des conteneurs dits
associatifs, c'est-à-dire qu'ils associent une clé à chaque
élément. Les données sont donc stockées par paire
(clé;élément) dans le conteneur, et sont triées par rapport
à la clé. Pour le conteneur map, il est possible d'accéder
directement à un élément à partir de sa clé, grâce
à l'opérateur []. Mais attention, si la clé n'est pas
présente dans le conteneur, une paire avec cette clé est automatiquement
créée et ajoutée au conteneur, l'élément associé est
construit par défaut.
Le conteneur map (respectivement le conteneur multimap) est en fait
un conteneur set (respectivement un conteneur
multiset) où les éléments sont des paires
(clé,élément). La STL fournit une structure pour représenter une
paire dont voici la définition.
template <typename T1,typename T2> struct pair {
T1 first;
T2 second;
pair(const T1 & a,const T2 & b) : first(a), second(b) {}
};
Ainsi, pour insérer un élément dans un conteneur map, il faut
d'abord créer une paire pour l'associer à sa clé, et ensuite fournir cette
paire à la méthode insert.
std::map<int,char *> m;
char * chiffres[] = { "zero", "un", "deux", "trois", "quatre",
"cinq", "six", "sept", "huit", "neuf" };
for (int i=0; i<10; ++i) {
m.insert(std::pair<int,char *>(i,chiffres[i]));
++i;
}
std::cout << "5 s'ecrit: " << m[5] << std::endl;
Pour insérer une paire, il faut le plus souvent la créer à la volée
en appelant son constructeur. Mais il faut tout de même préciser tous les
paramètres du template Pair pour réussir l'instanciation. Afin
d'éviter de préciser chaque fois ces paramètres, on utilise le patron de
fonction make_pair qui crée une paire à partir de deux
éléments. Voici tout d'abord la définition de ce patron.
template <typename T1,typename T2>
inline std::pair<T1,T2> make_pair(const T1 & a,const T2 & b)
{ return std::pair<T1,T2>(a,b); }
L'intérêt ici, c'est d'utiliser le polymorphisme statique fourni pour les patrons de fonction, comme le montre l'exemple suivant. Plus besoin de préciser les paramètres au template !
for (int i=0; i<10; ++i) {
m.insert(make_pair(i,chiffres[i]));
++i;
}
| ADAPTEURS |
Lorsqu'une classe ne convient pas totalement à une utilisation donnée, il est possible de l'adapter pour modifier ses fonctionnalités. Dans ce but, un design pattern nommé adapteur est proposé par le GoF. La bibliothèque STL a emprunté le nom adapteur pour désigner des classes permettant d'adapter le comportement des conteneurs de séquence. Trois classes sont proposées:
stack, pour adapter le conteneur au comportement d'une pile,queue, pour adapter le conteneur au comportement d'une file d'attente,priority_queue, pour adapter le conteneur au comportement d'une file d'attente à priorité.
Il faut bien comprendre que ces classes ne sont que des surcouches (on dit aussi
wrappers) aux classes vector, deque et list. Pour
créer un adapteur, il faut donc préciser le type de conteneur qu'on souhaite
adapter (comme le montre le schéma suivant).
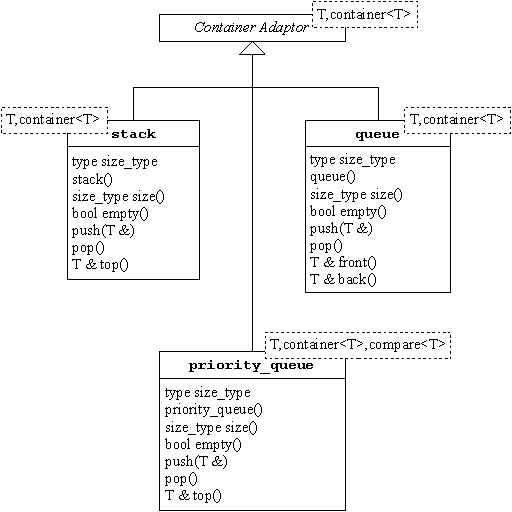
Dans le cas particulier de
la file d'attente à priorité, il faut également fournir un foncteur qui
permette de comparer les éléments, le plus grand étant le plus prioritaire. Ce
foncteur repose sur le même modèle que celui de la fonction sort par
exemple, et par défaut, le foncteur less est encore une fois utilisé.
Voici un exemple d'utilisation de cette file à priorité.
std::priority_queue<int,vector<int>,less<int> > q;
for (int i=0; i<10; ++i) q.push(std::rand());
for (int i=0; i<10; ++i) {
std::cout << q.top() << std::endl;
q.pop();
}
Des entiers sont ajoutés aléatoirement dans la file à priorité. Ils sont ensuite affichés du plus grand au plus petit.
| COMPLEXITE |
Nous n'avons absolument pas présenté ici la complexité des algorithmes et des opérations liées aux conteneurs. Ces informations nous semblent peu pertinentes ici, dans la mesure où nous ne proposons qu'un aperçu rapide de la bibliothèque. Mais nous vous invitons à consulter la documentation avant d'utiliser un conteneur ou un algorithme. La connaissance de la complexité d'une opération est fondamentale dans le choix du composant le mieux adapté à une situation donnée. La documentation fournie par SGI (cf. l'introduction de ce chapitre) fournit tous ces renseignements.
|