 |
7. L'APPROCHE ORIENTEE OBJET |
Ce chapitre est consacré à l'approche orientée objet et à l'introduction de ses principaux concepts. De nombreux ouvrages proposent d'excellentes présentations de ce domaine (e.g. [Booch91], [Meyer97], [Satzinger96]). Notre objectif ici n'est donc pas d'écrire une fois de plus un état de l'art des concepts du paradigme objet. Néanmoins, nous proposons une introduction suffisante pour qu'un débutant dans le domaine puisse suivre l'étude menée dans ce document (si celui-ci est désireux d'approfondir ces concepts, nous l'invitons à consulter l'un des ouvrages cités précédemment). Mais le but principal de ce chapitre est plutôt de discuter de l'apport de chacun des concepts à la réutilisabilité, et d'expliquer ainsi les différentes manières d'étendre un composant logiciel.
Dans ce document, toutes les modélisations orientées objet que nous présentons sont exprimées avec le langage UML (Unified Modeling Language [OMGWeb1]), qui est le formalisme le plus répandu. La présentation des concepts se déroule de manière à ce que la syntaxe du langage soit introduite naturellement. Tout lecteur qui souhaite plus d'information sur UML peut, par exemple, consulter l'ouvrage [Muller97a]. Les exemples de code que nous proposons sont proches de la syntaxe du langage C++, dont de nombreux livres d'apprentissage sont disponibles (e.g. [Lippman92], [Stroustrup97]).
Ce chapitre explique les avantages et les faiblesses des différents concepts de l'orientation objet, ce qui nous permet de justifier notre choix de langage pour l'implémentation de notre bibliothèque et d'entrevoir différentes possibilités de conception pour des composants logiciels réutilisables de recherche opérationnelle. Notre hésitation porte principalement entre Java et C++ qui sont les langages orientés objet les plus répandus, et donc les plus intéressants pour fournir une réutilisabilité logicielle.
| 7.1. OBJET ET CLASSE D'OBJET |
| 7.1.1. Définition d'un objet |
De nombreux langages orientés objet ont été développés depuis SIMULA, chacun apportant ses nouveaux concepts et parfois une vision différente de la notion d'objet. Il est donc difficile de proposer une définition simple et univoque d'un objet. Du point de vue de la programmation, nous avons vu au chapitre précédent qu'un objet est une entité encapsulant des données et des opérations, mais la véritable notion d'objet est beaucoup plus abstraite que cela. Parmi les nombreuses définitions données à un objet, nous retenons celle proposée dans [Booch91]: "Du point de vue de la conscience humaine, un objet correspond à l'une des définitions suivantes:
- Une chose palpable et/ou visible.
- Quelque chose qui peut être appréhendée intellectuellement.
- Quelque chose vers laquelle des pensées ou des actions sont dirigées."
A ces définitions, nous ajoutons simplement que dans le contexte du génie logiciel ou de la modélisation d'un système, un objet est considéré comme tel seulement s'il présente un intérêt pour l'étude menée. Un objet a naturellement des caractéristiques, appelées propriétés, qui définissent ce qu'il est. Ces propriétés peuvent être des caractéristiques de son comportement, ses méthodes, ou bien des caractéristiques de son état, ses attributs. En termes informatiques, les méthodes sont donc les opérations qu'un objet peut effectuer et les attributs sont ses données propres.
| 7.1.2. Classe d'objet |
Une classe d'objet représente une catégorie d'objets. Elle décrit un ensemble d'objets qui partagent des propriétés communes. Par partage d'attributs, on entend partage des types des attributs, et non des valeurs des attributs. Il faut distinguer le type d'un attribut, qui spécifie de quel genre de donnée il s'agit, de la valeur même de l'attribut. Pour renforcer cette différence, nous appelons structure l'ensemble des types des attributs d'un objet. En résumé, une classe décrit les opérations et la structure communes d'un ensemble d'objets (cf. figure 7.1a pour la notation UML).
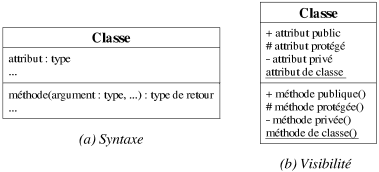 |
| Figure 7.1: Représentation d'une classe. |
Comme pour un type de donnée classique, il est possible, à partir d'un modèle qu'est une classe, de créer des objets. L'action de créer un objet à partir d'une classe est appelée instanciation de la classe (cf. figure 7.2, (b) montre la notation UML d'un objet), et l'objet est désigné comme une instance de cette classe.
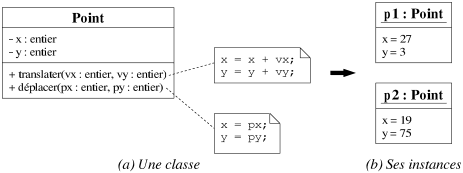 |
| Figure 7.2: Un exemple d'instanciation d'une classe. |
Une classe peut être vue comme un objet, c'est-à-dire posséder ses propres propriétés. Pour distinguer les propriétés d'une classe des propriétés de ses objets, on parle respectivement de propriétés de classe et de propriétés d'instance. Pour assurer le principe d'encapsulation, certaines propriétés peuvent être cachées, soient partiellement, soit complètement. Les propriétés sont privées si elles sont cachées de tous (excepté de leur classe bien entendu), protégées si elles sont visibles seulement de certaines classes (les sous-classes de leur classe, cf. section 7.2 pour les détails) et publiques si elles sont visibles par tous. La figure 7.1b précise les notations employées avec UML pour représenter les différents concepts introduits dans ce paragraphe.
Au chapitre précédent, nous avons défini l'interface et l'implémentation d'un type abstrait de donnée et par conséquent d'une classe. Voici cependant quelques précisions importantes. L'interface d'une classe décrit simplement ses services publics (c'est-à-dire les types de ses attributs publics et uniquement les signatures de ses méthodes publiques). L'implémentation d'une classe décrit tout ce qu'elle doit cacher des utilisateurs (ses propriétés privées ou protégées et le corps de toutes ses méthodes, quelque soit leur visibilité).
| 7.1.3. Envoi de message |
Les méthodes d'un objet sont les seules capables de modifier ses attributs
cachés. Si un objet a veut modifier l'un des attributs de l'objet
b, il doit passer par les méthodes de l'interface (i.e. les
propriétés publiques) de b. L'objet a doit donc effectuer
une demande, appelée message, auprès de b. La figure 7.3 illustre
un tel envoi de message, a demande à b de modifier son attribut
x en appelant la méthode setX(), le message étant
émis à partir de la méthode calcul() de a. La figure
emprunte sa notation d'un envoi de message aux langages C++ et Java: étant donné un
objet a, l'accès à un attribut x ou l'appel d'une
méthode f() se note respectivement a.x et a.f().
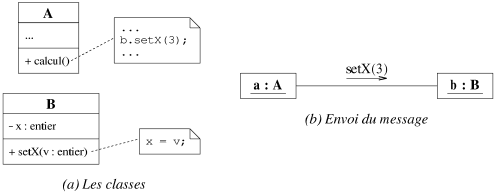 |
| Figure 7.3: Un exemple d'envoi de message entre objets. |
Le terme message prend plus de sens dans les systèmes où les objets "vivent" en parallèle comme dans un système multithread, multitâche ou même distribué, où l'envoi d'un message au sens orienté objet correspond à un véritable échange de messages entre tâches, threads ou ordinateurs. Un envoi de message est alors une requête qui peut ne pas aboutir ou être mise en attente si l'objet sollicité est occupé. Un envoi de message ne se résume donc pas toujours à un simple appel de méthode, même en excluant la problématique du parallélisme. Dans la suite du chapitre, nous verrons que certains concepts orientés objet nécessitent un mécanisme d'envoi de message assez complexe, entraînant un surcoût de l'encapsulation souvent incriminée pour expliquer la lenteur d'un programme orienté objet.
| 7.1.4. Construction et destruction d'un objet |
La vie d'un objet est divisée en trois grandes étapes: sa création, sa vie
proprement dite et sa suppression. La création se déroule en deux temps:
l'allocation et la construction. Tout d'abord, une zone mémoire est
allouée pour stocker les attributs de l'objet. Ensuite, une méthode spéciale
de l'objet est appelée, le constructeur, chargée d'initialiser les attributs.
Des arguments peuvent être passés à cette méthode. La figure 7.4 montre
pour la classe Point un constructeur prenant en paramètres les deux
coordonnées du point. Ainsi, l'instruction new Point(cx,cy) crée un
objet de la classe Point avec les coordonnées (cx;cy).
La suppression d'un objet se déroule également en deux temps: la
destruction et la libération. Tout d'abord, une méthode spéciale
de l'objet est appelée, le destructeur, chargée de préparer l'objet
à sa suppression. Ensuite, la mémoire occupée par les attributs de l'objet est
libérée. Aucun argument ne peut être passé au destructeur. Le rôle
classique du destructeur est de libérer la mémoire que l'objet a pu allouer au cours
de sa vie. Mais il peut servir également à prévenir d'autres objets de sa
suppression (e.g. un arc peut informer le graphe auquel il appartient de sa suppression). La figure
7.4 montre pour la classe Cercle un destructeur qui supprime l'attribut
centre créé par le constructeur de la classe. Ainsi, l'instruction
delete centre supprime l'objet référencé par centre.
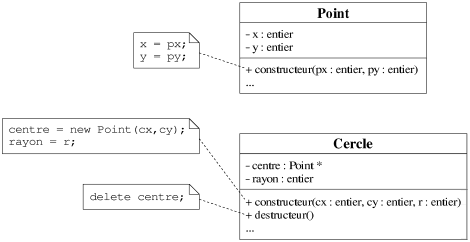 |
| Figure 7.4: Un exemple de constructeur et de destructeur. |
Dans ce document, nous ferons la différence entre une variable ou un attribut qui est un
objet d'une classe A, dont le type sera A, et une référence
(ou un pointeur, nous ne faisons pas ici de distinction entre les deux termes), dont le type sera
A *, pour indiquer qu'il s'agit simplement d'un moyen
d'accéder à un objet de type A. L'instruction new renvoie
donc une référence sur l'objet qu'elle vient de créer.
| 7.2. HERITAGE |
| 7.2.1. Principe |
L'héritage est certainement le concept le plus novateur du paradigme objet, mais un mauvais usage peut entraîner des surconsommations mémoire ou processeur importantes. C'est la raison principale pour laquelle les langages objets sont considérés lents par rapport aux langages procéduraux. L'efficacité étant un facteur important pour la recherche opérationnelle, l'héritage mérite une présentation détaillée, aussi bien au niveau des concepts qu'au niveau de l'implémentation, afin d'identifier précisément les sources de surconsommations.
Nous avons expliqué qu'une classe décrit un ensemble d'objets ayant des
caractéristiques communes. Il peut y avoir des classes très générales
comme des classes très spécifiques. L'héritage consiste en une
spécialisation d'une classe. Lorsqu'une classe B hérite d'une classe
A, cela signifie que les instances de la classe B appartiennent
également à la classe A, mais avec des propriétés
supplémentaires propres aux instances de B. La classe A est
appelée super-classe de B et B sous-classe de
A, en rapport avec la structure hiérarchique que forme l'héritage. La
figure 7.5 montre un exemple d'héritage où la classe Dessin
possède deux sous-classes Rectangle et Point. Lorsque l'on passe
d'une classe à l'une de ses sous-classes, on parle de spécialisation. A
l'inverse, lorsque l'on passe d'une classe à l'une de ses super-classes (en effet, une
classe peut hériter de plusieurs classes, e.g. [Hill96]), on
parle de généralisation.
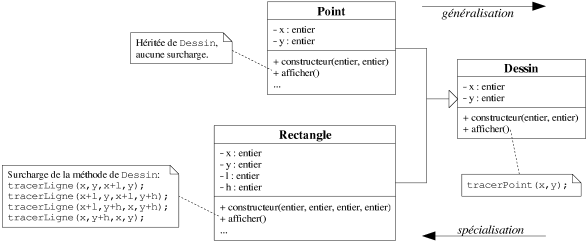 |
| Figure 7.5: Un exemple d'héritage. |
Qu'une classe B hérite d'une classe A signifie que
B possède l'interface de A et profite par conséquent de
l'implémentation de A. On dit que B hérite à la fois
de l'interface (i.e. une instance de B répond aux mêmes messages que
A) et de l'implémentation de A (i.e. le comportement en
réponse aux messages est le même). Cependant, B ne peut accéder
qu'aux propriétés publiques et protégées (d'où
l'intérêt de ce niveau de visibilité) de sa super-classe, mais elle n'a
accès en aucun cas aux propriétés privées. Enfin, pour se
spécialiser, une sous-classe possède son propre complément d'interface et
d'implémentation.
| 7.2.2. Méthode virtuelle |
Une sous-classe peut également modifier le comportement d'une méthode d'instance
héritée, en remplaçant l'implémentation de la super-classe par la
sienne (uniquement à son niveau, car la super-classe conserve naturellement son
implémentation). On parle alors de surcharge de méthode. Reprenons l'exemple
de la figure 7.5 où les classes Rectangle et Point héritent
de la classe Dessin. La super-classe possède une méthode
afficher() surchargée dans les deux sous-classes. Considérons maintenant
le code suivant.
Dessin * obj1 = new Dessin(10,20);
Dessin * obj2 = new Point(30,40);
Dessin * obj3 = new Rectangle(0,50,100,60);
obj1.afficher();
obj2.afficher();
obj3.afficher();
Les variables obj1, obj2 et obj3 sont trois
références sur des objets de la classe Dessin (ou l'une de ses
sous-classes). Les trois dernières lignes de l'exemple ont donc toutes les trois la
même signification: appeler la méthode afficher() de l'objet de la classe
Dessin référencé. Pour obj1, le comportement est
assez clair, c'est la méthode de la classe Dessin qui est appelée. Pour
obj2, là aussi, c'est la méthode de Dessin qui est
appelée, puisque Point hérite de la méthode sans la surcharger.
En revanche, pour obj3, est-ce la méthode de Dessin qui est
appelée, ou bien est-ce la méthode surchargée de Rectangle ?
La réponse dépend de la nature de la méthode: si afficher()
est virtuelle alors c'est la version de Rectangle qui est appelée, sinon
c'est celle de Dessin. Le fait qu'une méthode soit virtuelle signifie
qu'au moment de son appel, c'est sa version la plus spécialisée (en s'arrêtant
bien entendu à la classe réelle de l'objet sur lequel la méthode est
appliquée) qui est appelée. Si une méthode n'est pas virtuelle, nous
l'appelons finale (en rapport avec le mot clé final de Java). Selon les
langages, les méthodes sont considérées par défaut virtuelles (e.g.
Java) ou finales (e.g. C++), et un mot-clé permet de les faire changer de catégorie
(e.g. final pour Java, virtual pour C++). Dans nos schémas, nous
considérons toujours, sauf précision de notre part, des méthodes virtuelles.
| 7.2.3. Polymorphisme |
La surcharge de méthode consiste à fournir une nouvelle implémentation à une méthode existante. Le fait qu'une méthode puisse prendre plusieurs formes est également appelé polymorphisme. La surcharge d'une méthode virtuelle est une forme de polymorphisme dite dynamique puisque l'implémentation qui est appelée est choisie au moment de l'envoi du message. Il existe également une forme de polymorphisme statique où la sélection de l'implémentation de la méthode est effectuée à la compilation. Nous verrons deux exemples de ce type de polymorphisme. L'un est abordé en détail dans la section 7.4 concernant les patrons de composant.
L'autre consiste en une manière de surcharger une méthode différente de la virtualité et indépendante de l'orientation objet. Dans la plupart des langages actuels, il est possible de surcharger une méthode (ou une fonction) en proposant des méthodes avec le même nom mais des signatures différentes. Voici un exemple simple.
function max(entier,entier) : entier;
function max(réel,réel) : réel;
...
max(100,200);
max(2.5,2.25);
Deux méthodes max() ont le même nom. Pour identifier quelle version
est appelée, il suffit de regarder le type des paramètres fournis à la
méthode, ce qui peut être effectué à la compilation. Ce type de
surcharge n'est pas fondamental pour la réutilisabilité, mais il apporte une certaine
simplicité dans l'utilisation des méthodes tout à fait appréciable. En
outre il est très intéressant au niveau de la maintenabilité, e.g. un
remplacement des variables entières par des variables réels dans un programme
n'entraîne aucun changement des appels à la méthode max().
En défaveur de la maintenabilité, cette surcharge statique peut entraîner
de graves confusions. Imaginons l'appel max(2,2.5). Dans la plupart des langages, le
nombre entier est converti implicitement en un nombre réel et c'est donc la version
réelle de max() qui est appelée. Supposons maintenant qu'au cours d'une
phase de maintenance, une version max(entier,réel) soit ajoutée, pour
des besoins totalement indépendants de la partie de code que nous étudions. Dans ce
cas, notre conversion implicite n'a plus lieu d'être et c'est la nouvelle méthode qui
est appelée. Ainsi, une modification dans le programme totalement indépendante de
notre partie de code entraîne un changement significatif dans ce même code, ce qui peut
être catastrophique si la nouvelle version a des fonctionnalités totalement
différentes des anciennes.
Nous pensons donc que cette surcharge statique peut tout à fait être utilisée lorsqu'il s'agit de méthodes dans une classe (la portée de la maintenance est relativement contrôlée: il est impossible de confondre une méthode d'une classe avec celle d'une autre), mais doit être évitée pour les fonctions (la portée de la maintenance est difficile à définir, à moins d'employer un concept comme l'espace de nommage, e.g. le namespace en C++).
| 7.2.4. Réutilisabilité |
Pour promouvoir le paradigme objet, il n'est pas rare de trouver des références qui affirment que l'héritage offre un haut degré de réutilisabilité (cf. [Johnson88]). Il est important de discuter ce point. En effet, l'héritage permet à une sous-classe de s'approprier les fonctionnalités de sa super-classe et de les adapter à ses besoins, permettant ainsi beaucoup d'extensibilité. Il s'avère cependant que pour permettre suffisamment d'extensions, la sous-classe potentielle doit voir des éléments de l'implémentation (i.e. des propriétés cachées) de sa super-classe, d'où la possibilité de définir des propriétés protégées. Malheureusement, cela introduit une brèche dans l'encapsulation de la super-classe qui peut se révéler néfaste pour la maintenabilité des composants, puisqu'une légère modification dans l'implémentation de la super-classe peut se répercuter à toutes les sous-classes.
Pour garantir une certaine maintenabilité, l'interface d'une classe est un élément qu'il faut éviter de changer (seuls des ajouts n'ont pas d'impact). Il faut donc bien réfléchir et être perspicace au moment de son élaboration. Pour les mêmes raisons, la partie protégée d'une classe, étant une interface pour ses sous-classes, ne devrait pas être changée. Malheureusement, il est très difficile de ne pas modifier l'implémentation d'une classe, c'est ce qui la fait évoluer, et l'on constate généralement que l'interface d'une classe a moins souvent besoin d'être changée que son implémentation (cf. [Meyer97]).
L'héritage fournit en revanche le polymorphisme dynamique, qui est un concept
très puissant. Il permet en effet une forte abstraction des objets. Des composants peuvent
être développés manipulant un type d'objet très abstrait, utilisant
uniquement l'interface de cette classe abstraite. Ensuite, n'importe quel objet héritant de
cette classe peut être manipulé par les composants. On obtient alors un
découplage fort entre les objets et les composants qui les utilisent, ce qui favorise la
maintenabilité et un fort potentiel de réutilisabilité. Le polymorphisme
dynamique est beaucoup utilisé pour des traitements massifs. Prenons comme exemple un
tableau de références sur des objets de la classe Dessin (cf. figure
7.5). Un simple parcours, comme le montre l'exemple suivant, permet d'afficher tous les objets du
tableau.
Dessin * t[] = ...;
for i = 0 to t.size() do
t[i].afficher();
end for;
En résumé, la spécialisation fournie par l'héritage offre une bonne extensibilité mais peut conduire à une mauvaise maintenabilité. En revanche, le polymorphisme dynamique de l'héritage permet un fort découplage des composants logiciels entraînant une bonne réutilisabilité et maintenabilité. Un petit détail peut cependant modérer l'utilisation du polymorphisme dynamique: il faut que la personne qui conçoit la classe de base (classe au sommet de la hiérarchie d'héritage qui nous intéresse) déclare la méthode virtuelle. Et il est toujours délicat d'anticiper les besoins des réutilisateurs. Malheureusement, comme nous l'expliquons dans une prochaine section, la virtualité a un coût et il n'est pas envisageable de considérer toutes les méthodes virtuelles.
| 7.2.5. Coût de l'encapsulation |
Une idée généralement fausse est que l'encapsulation, i.e. le fait
accéder à certains attributs par l'intermédiaire d'une méthode, a
toujours un coût. Prenons l'exemple très simple d'un attribut x dans une
classe A. Nous pouvons choisir de mettre x en public s'il peut être
modifié à volonté de l'extérieur de la classe. Cependant, beaucoup
préconisent une approche où x est privé (ou
protégé) et possède deux méthodes getX() et
setX() qui permettent respectivement d'obtenir et de modifier la valeur de
x. Ce surplus d'écriture peut paraître dans un premier temps superflu,
mais il est en fait très important pour la réutilisabilité. Tout d'abord, il
faut éviter que l'utilisateur se pose la question de savoir si la donnée
x est un attribut ou bien le résultat d'un calcul. Dans un simple souci
d'homogénéité, il est donc important qu'une donnée soit toujours
accédée par une méthode. Ensuite, il est possible qu'au cours du temps une
donnée qui était un attribut devienne une donnée calculée (e.g. la
longueur d'un arc peut être fixée ou calculée en fonction des
coordonnées de ses extrémités). Pour renforcer la maintenabilité, nous
recommandons donc de toujours encapsuler les données. Mais cette encapsulation
systématique n'a-t-elle pas un impact sur le temps d'exécution ? Si la méthode
permettant accéder à un attribut est virtuelle, l'appel a en effet un coût non
négligeable. En revanche, lorsqu'il s'agit d'une méthode finale, le coût est
identique à un appel à une fonction, voire moins. Il est généralement
possible que certaines méthodes soient définies inline (soit par
l'utilisateur, soit automatiquement par le compilateur).
C'est-à-dire que le mécanisme d'appel de fonction n'est pas utilisé, à la place le code de la méthode est directement recopié à l'endroit de l'appel. Cela revient donc exactement à ce que le programmeur réécrive le corps de la méthode directement à chaque endroit où il en a besoin. Le bénéfice direct est qu'il n'y a pas de mécanisme d'appel à une fonction, qui est relativement coûteux (sauvegarde du contexte avant l'appel, recopie des paramètres...). Le bénéfice indirect est que le compilateur peut éventuellement effectuer une optimisation qu'il n'aurait pas pu faire avec l'appel de fonction. Des expérimentations menées dans [Lippman97] (cf. sa table 3.1) montrent pour C++ que l'accès à une variable locale est tout aussi coûteux que l'accès encapsulé par une méthode inline à l'attribut d'un objet. L'encapsulation n'a donc aucun coût, si ce n'est un peu plus de code source à écrire, et elle renforce l'homogénéité et la maintenabilité des composants.
| 7.2.6. Coût de la virtualité |
L'encapsulation n'a finalement un coût que lorsqu'une méthode virtuelle est appelée. Mais quel est exactement l'impact d'un appel à une méthode virtuelle plutôt qu'à une méthode finale ? Nous proposons d'expliquer succinctement le mécanisme mis en oeuvre lors d'un polymorphisme dynamique. Nous espérons que cela permettra au lecteur de mieux juger de la pertinence d'employer l'héritage et donc la virtualité par rapport à une autre technique. Le petit résumé que nous exposons ici est extrait de [Lippman97] et [Driesen96] qui expliquent dans les détails, avec la prise en compte de nombreux aspects que nous passons ici sous silence, comment un appel à une méthode virtuelle est réalisé.
L'idée originale est très simple. Lorsqu'un objet appartient à une classe
qui possède une méthode virtuelle ou hérite d'une méthode virtuelle,
alors il possède un attribut supplémentaire, une référence,
appelée pointeur virtuel ou v-pointeur, qui pointe sur un tableau,
appelé table virtuelle ou v-table. Cette table, unique pour chaque classe,
contient les pointeurs des implémentations des méthodes virtuelles qu'un objet
effectivement de la classe (i.e. n'appartenant pas à l'une des sous-classes) peut appeler.
La figure 7.6 illustre le mécanisme d'appel à une fonction virtuelle avec cette
structure. La figure considère une référence sur un objet de la classe
Dessin. Pour appeler la méthode virtuelle afficher(), qui
possède trois implémentations selon que l'objet appartienne à l'une des trois
classes, il suffit accéder à la v-table référencée par le
v-pointeur de l'objet et d'exécuter l'implémentation de la méthode
afficher() qui s'y trouve.
Le surcoût engendré par le polymorphisme dynamique semble assez immédiat à évaluer. Au lieu d'appeler une simple fonction, il faut tout d'abord accéder à la table virtuelle de l'objet, et ensuite il faut trouver la méthode appelée dans cette table. Ces deux étapes ne se résument pas toujours à une simple indirection de pointeur, à cause de contraintes liées à des concepts que nous aborderons très peu, voire pas du tout dans ce document: héritage multiple, héritage virtuel, information de type en temps réel (e.g. RTTI en C++)...
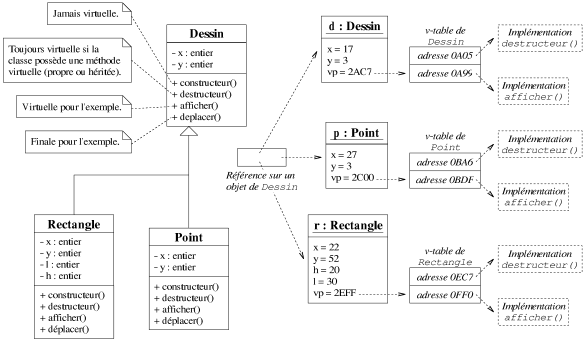 |
| Figure 7.6: Polymorphisme dynamique et table virtuelle. |
Le tableau 7.1, extrait de [Lippman97] (table 4.1) et confirmé par le rapport [ORiordan02] d'un groupe de standardisation ISO/IEC, fournit des résultats intéressants sur le coût d'un appel à une fonction virtuelle. Le test a consisté à appeler un nombre important de fois une même méthode (contenant seulement quelques lignes de calculs simples), cette méthode étant tout d'abord inline, puis une méthode de classe (techniquement équivalente à une fonction), une méthode d'instance finale et enfin une méthode virtuelle (issue d'un héritage simple comme nous l'avons défini, mais également d'un héritage multiple ou virtuel, hors de propos ici, mais dont le résultat est intéressant pour ceux qui connaissent). Les résultats sont présentés sans optimisation du compilateur, afin d'isoler le coût direct de la virtualité, et ensuite avec les optimisations de manière à entrevoir le potentiel des coûts indirects.
Ce tableau montre tout d'abord pour une méthode simple que la suppression de la propriété inline entraîne une augmentation de 30 % du temps d'exécution. Ce coût étant fixe, l'impact tend à être négligeable plus les fonctions sont longues à exécuter. Il faut également noter qu'une méthode inline est dupliquée dans le code compilé autant de fois qu'elle est appelée. Dans un développement logiciel à grande échelle, comme une bibliothèque, cela peut entraîner un accroissement de la taille du code compilé très important, voire démesuré, qui est en relation directe avec le temps et la mémoire utilisés pour la compilation. Précisons aussi que le corps d'une méthode inline publique doit être dans l'interface de la classe, afin qu'il soit possible, à l'extérieur de la classe, de dupliquer le corps de la méthode à l'endroit de son appel. Enfin en mode optimisé, on remarque que le fait d'être inline a permis une très importante amélioration du code de la méthode impossible sinon.
Regardons maintenant le passage à une méthode virtuelle, l'impact n'est pas aussi important que la "rumeur" le laisse croire. En effet, en mode non optimisé, la virtualité introduit un ralentissement de 13 %, ce qui est assez important. En mode optimisé, l'impact est pratiquement divisé par deux, 7 %, ce qui est non négligeable mais pas catastrophique pour la plupart des applications. Cependant, dans certains cas d'héritage (e.g. virtuel), l'impact monte à 17 %. L'inconvénient de ces résultats est qu'ils reposent sur une seule expérimentation. [Driesen96] a mené une étude sur une dizaine de logiciels existants. Elle a consisté à simuler les programmes pour évaluer le coût direct de la virtualité, tout d'abord en supposant que les appels aux méthodes virtuelles étaient miraculeusement aussi performants que des appels à de simples fonctions. Ensuite, des simulations avec le mécanisme réel de virtualité ont été effectuées et les temps simulés d'exécution ont été comparés. Les résultats révèlent qu'en moyenne les programmes perdent 5,2 % de leur temps dans l'appel aux méthodes virtuelles et dans le pire des cas 29 %. Une autre expérimentation a consisté à remplacer tous les appels aux méthodes par des appels virtuels, le résultat est une moyenne de 13,7 % de perte de temps avec un maximum de 47 %.
|
|||||||||||||||||||||||||||||||||||||||
| Tableau 7.1: Coût de la virtualité. | |||||||||||||||||||||||||||||||||||||||
Nous verrons par la suite que l'héritage et en particulier les appels virtuels sont la cause majeure de l'inefficacité de certains programmes orientés objet par rapport à une approche procédurale. Néanmoins, les études rappelées ici tendent à le montrer, il ne s'agit pas d'un facteur de 100 % ou plus comme certaines "rumeurs" le prétendent. Cependant, il faut reconnaître qu'un abus du polymorphisme dynamique peut conduire à ce genre de mauvaises performances. La suite du chapitre a donc pour but de montrer comment contourner dans certains cas l'héritage et la virtualité, et donc de maintenir une efficacité raisonnable des composants.
| 7.3. COMPOSITION, AGREGATION ET ASSOCIATION |
| 7.3.1. Différences conceptuelles |
Nous présentons ici trois types de relation similaires entre classes: la composition,
l'agrégation et l'association. Les deux premières expriment l'appartenance d'un objet
à un objet plus vaste. Elles traduisent l'action "possède" ou "est
composé(e)" entre un composé et ses composants. Par exemple, la relation
"un graphe est composé d'arcs et de noeuds" se traduit par une composition entre
la classe Graphe et les classes Arc et Noeud (cf. figure
7.7). Dans une composition, les composants (e.g. les arcs ou les noeuds) n'ont pas d'existence en
dehors de leur composé (e.g. le graphe). La vie des composants est donc liée
directement à celle du composé. L'agrégation diffère de la composition
sur ce point, les composants ont une vie propre et n'appartiennent à un composé que
pour une durée limitée. Notamment, dans une agrégation, la destruction du
composé n'entraîne pas la destruction des composants, contrairement à la
composition. Par exemple, la relation "un cycle est composé d'arcs" est traduite
par une agrégation entre la classe Cycle et la classe Arc (cf.
figure 7.8).
|
|
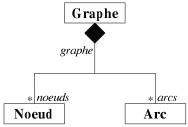
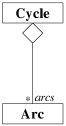
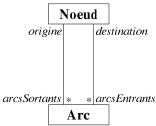
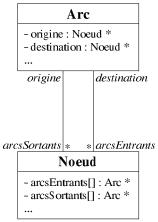
L'association diffère des deux autres relations par le fait qu'il n'y ait pas de
dominance de l'une des deux classes impliquées. Par exemple, la relation "un arc
possède un noeud origine et un noeud destination" se traduit par deux associations
entre la classe Arc et la classe Noeud (cf. figure 7.9). Pour une
association entre deux classes, il est possible de spécifier combien de relations il peut
effectivement exister entre des instances de ces classes, simplement en apposant une
cardinalité sur l'association. Dans la figure 7.9, l'arc possède un noeud origine et
un noeud destination, donc la cardinalité du point de vue de l'arc est 1 pour les deux
associations. En revanche du point de vue du noeud, l'association peut aller de 0 à
n, d'où le symbole * pour symboliser cette
cardinalité. Une cardinalité explicite peut être apposée (e.g.
1..4).
 |
| Figure 7.9: Un exemple d'association. |
| 7.3.2. Similitudes d'implémentation |
Ces trois relations, dont la différence est très importante au niveau conceptuel, sont quasiment identiques au niveau de l'implémentation. Toutes les trois sont en effet traduites par la présence d'attributs des classes composants dans la classe composé.
 |
| Figure 7.10: Un exemple d'implémentation (avec attributs objets) d'une composition. |
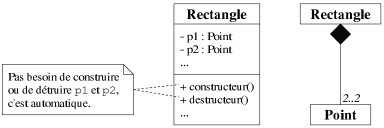
Pour commencer, tout attribut objet d'une classe représente forcément une
composition entre la classe possédant l'attribut et la classe indiquant le type de
l'attribut. Par exemple, la figure 7.10 représente une classe Rectangle
possédant deux attributs de la classe Point. Il s'agit d'une composition
puisque les composants (i.e. les attributs) sont créés et supprimés en
même temps que le composé (i.e. un objet de la classe). Plus
précisément, lorsque le constructeur (respectivement le destructeur) de
Rectangle est appelé, les constructeurs (respectivement les destructeurs) de
p1 et p2 sont automatiquement exécutés.
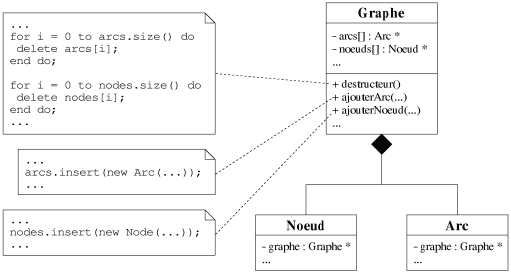
Reprenons l'exemple de la composition de la figure 7.7, la classe Graphe
possède deux attributs arcs et noeuds, deux listes de
références respectivement d'arcs et de noeuds (cf. figure 7.11). Les attributs
induits par une composition peuvent donc être des références, la classe
composé doit alors gérer la création et la suppression des composants (cf.
figure 7.11).
 |
| Figure 7.11: Un exemple d'implémentation (avec attributs références) d'une composition. |
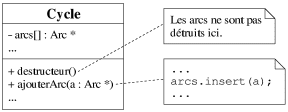
L'agrégation et l'association se traduisent également par des attributs
références d'objets. Dans l'exemple de l'agrégation (cf. figure 7.8), la
classe Cycle possède un attribut arcs qui est une liste de
références sur des objets de la classe Arc (cf. figure 7.12). Dans
l'exemple d'association (cf. figure 7.9), la classe Arc possède deux attributs,
origine et destination qui sont des références sur des
objets de la classe Noeud (cf. figure 7.13). Cette dernière possède deux
attributs arcsEntrants et arcsSortants qui sont des listes de
références d'objets de la classe Arc.
 |
| Figure 7.12: Un exemple d'implémentation d'une agrégation. |
Ces trois relations, que nous résumerons par le terme composition dans la suite du document afin de faciliter la discussion, sont une possibilité supplémentaire de réutilisabilité. Par l'assemblage d'objets, il est possible d'en construire un plus complexe et de lui ajouter des fonctionnalités. Contrairement à l'héritage, il n'est pas possible de modifier les fonctionnalités des objets réutilisés, en revanche il est possible de les faire interagir pour produire des fonctionnalités plus complexes. Cela suppose de la part des composants fournis d'être très complets pour pouvoir être adaptés à de nombreux besoins. C'est donc le principal défaut de ce type de réutilisation: si le concepteur de l'objet réutilisé n'a pas prévu une fonctionnalité, elle ne peut pas toujours être rajoutée (e.g. si l'accès à un élément privé est nécessaire). L'avantage majeur en revanche est la réutilisation en boîte noire des classes, ce qui apporte une grande indépendance entre les composants et leur composé. Une modification de l'implémentation d'un composant n'entraîne aucune modification pour le composé, ce qui est tout à fait différent de l'héritage, qui est une réutilisation en boîte blanche (cf. [Gamma95]), et qui apporte une dépendance forte entre la super-classe et ses sous-classes.
 |
| Figure 7.13: Un exemple d'implémentation d'une association. |
| 7.3.3. Délégation |
La tentation avec l'approche objet est grande d'utiliser l'héritage chaque fois que l'on souhaite étendre un composant (cf. [Johnson88], l'approche programming-by-difference). C'est la solution de facilité. On a besoin de modifier la fonctionnalité d'une classe, il suffit d'hériter, de modifier les quelques méthodes qu'il faut et c'est terminé. Outre le nombre important de classes que cela peut produire, nous avons déjà discuté des problèmes de maintenabilité qu'entraîne l'héritage. Tout cela peut conduire à long terme à une hiérarchie d'héritage complexe où le réutilisateur se perd (cf. [Gamma95]), ce qui est dommage quand on sait que l'un des objectifs majeurs du paradigme objet est de fournir une vision claire de la structure d'un logiciel.
En outre, la hiérarchie fournie par l'héritage est statique, cela veut dire qu'au
cours de l'exécution du programme, il n'est pas possible de modifier l'héritage d'une
classe pour qu'un objet héritant des fonctionnalités d'une classe puisse
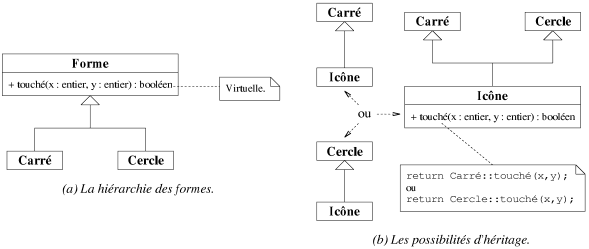
hériter de celles d'une autre. Considérons l'exemple de la figure 7.14a qui
présente une hiérarchie d'héritage avec une classe de base Forme
spécialisée en deux sous-classes Carré et Cercle.
Une classe Icône doit hériter des propriétés d'une des
classes Forme.
 |
| Figure 7.14: Un exemple de l'intérêt de la délégation. |
Comme le montre la figure 7.14b, il est possible de décider statiquement de la forme de
l'icône par un héritage de Carré, de Cercle ou des
deux (c'est ce que l'on appelle l'héritage multiple). Imaginons maintenant que l'on
souhaite savoir si un clic de souris a atteint un objet Icône. Il suffit alors
d'appeler la méthode touché() avec en paramètre les
coordonnées de la souris. Pour l'héritage simple, la méthode
héritée est appelée. Pour l'héritage multiple, il faut faire le choix
d'appeler la méthode de Carré ou de Cercle au moment de
l'écriture de la classe Icône (cf. figure 7.14b).
Mais comment faire pour permettre à un tel objet de changer sa forme en cours
d'exécution et bien entendu d'hériter des caractéristiques de sa nouvelle
forme ? Grâce à la composition, il est possible de changer dynamiquement la forme de
l'objet Icône. Cette technique est appelée
délégation (cf. [Johnson91]). Elle consiste pour la
classe qui hérite à agréger un objet de la classe dont elle veut les
fonctionnalités. Elle fournit ensuite une interface identique à celle de l'objet
agrégé. Chaque fois qu'une de ses méthodes est appelée, elle
délègue l'appel, i.e. elle appelle la méthode homonyme de l'attribut qu'elle
agrège. Dans notre exemple, il suffit que Icône agrège un objet de
la classe Forme, pouvant être changé par la méthode
setForme(). Ainsi, chaque fois qu'elle est appelée, la méthode
touché()touché() de son attribut forme.
 |
| Figure 7.15: Un exemple de délégation. |
La délégation est une technique intéressante pour remplacer
l'héritage. Elle fournit une forme de polymorphisme dynamique gérée en partie
par le concepteur. Cependant, elle nécessite toujours le polymorphisme de l'héritage,
ici pour la méthode touché() de la classe Forme.
L'intérêt est donc principalement le dynamisme de ce pseudo-héritage. Mais il
faut se méfier de la complexité (liée à l'augmentation des
paramètres de la classe) qu'apporte cette technique dans l'utilisation du composant.
[Gamma95] conseille donc d'employer cette technique avec
modération, quand cela est réellement nécessaire (c'est le cas de notre
exemple), et surtout quand cela simplifie la conception.
| 7.4. PATRON DE COMPOSANT |
Au niveau de sa mise en oeuvre, le concept de patron est certainement l'un des plus complexes de l'orientation objet. C'est la raison pour laquelle il a fallu attendre des années avant que C++ l'exploite pleinement et que ses compilateurs fournissent un standard sur cet aspect. Cela explique aussi probablement que Java n'ait pas implémenté initialement ce concept, ce qui lui fait aujourd'hui défaut, même si des tentatives pour l'ajouter sont actuellement en cours.
| 7.4.1. Patron de fonction, méta-fonction |
Un patron de fonction, ou une méta-fonction, est un moyen d'écrire
un modèle d'une fonction paramétré sur certains types des données
qu'elle manipule. Par exemple, considérons une fonction max() qui retourne le
maximum de deux nombres. Nous avons vu à la section 7.2 qu'une forme de polymorphisme
statique est possible, simplement en créant une fonction avec le même nom
max() pour chaque type de nombre que l'on souhaite prendre en charge. Il faut alors
créer autant de fonctions qu'il y a de types de nombre, ce qui n'est pas gênant
lorsque les contenus de ces fonctions sont fondamentalement différents. Mais dans notre
exemple, les corps des fonctions sont identiques:
if (n1 < n2) return n2;
else return n1;
L'idéal serait donc de pouvoir considérer le type des nombres manipulés
comme un paramètre. C'est exactement ce que permet le patron de fonction. Pour notre
exemple, nous proposons une méta-fonction max() de paramètre
T, que l'on note max<T>().
function max<T>(n1 : T, n2 : T) : T
if (n1 < n2) return n2;
else return n1;
end function;
Pour simplifier notre discussion, nous appelons arguments les paramètres
classiques d'une fonction (e.g. n1 et n2), et réservons le terme
paramètres à ceux du patron (e.g. T). La méta-fonction
max<T>() est un modèle qui permet de créer des fonctions
max() où le type de T est connu. Une telle fonction est
identifiée en remplaçant les paramètres de la méta-fonction par les
types choisis pour la fonction. Par exemple, la fonction max() pour les réels
sera identifiée max<réel>() et sera utilisée de la
manière suivante.
max<réel>(2,5);
Il est également possible de profiter d'un polymorphisme statique et de ne pas
spécifier explicitement les paramètres fournis à la méta-fonction.
L'exemple suivant appelle la fonction max<entier>() pour la première
ligne et max<réel>() pour la seconde.
max(2,5);
max(2.5,2.4);
Ce polymorphisme statique (identique à celui présenté à la section 7.2, i.e. avec les mêmes avantages et défauts) est possible uniquement si les types des arguments de la fonction permettent de déterminer tous les paramètres de la méta-fonction. Il est en effet tout à fait possible de paramétrer une méta-fonction sur un type qui n'est utilisé qu'à l'intérieur de la fonction (e.g. une structure de données temporaire pour un algorithme).
| 7.4.2. Patron de classe, méta-classe |
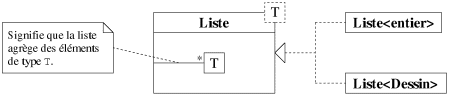
Les patrons de fonction ouvrent une nouvelle perspective de réutilisabilité des opérations. Les patrons de classe, tout à fait similaires, offrent la même approche pour les structures de données. Un patron de classe, ou une méta-classe (appelée aussi classe générique, classe paramétrée ou template), est un moyen d'écrire un modèle d'une classe paramétré sur certains types des données qu'elle manipule (les attributs, les arguments des méthodes ou les variables locales). Un exemple classique est une classe représentant une liste d'éléments, la classe étant paramétrée sur le type des éléments qu'elle agrège.
 |
| Figure 7.16: Un exemple de patron de classe. |
La figure 7.16 illustre la notation d'une telle méta-classe en UML et montre la relation
qu'il existe entre une méta-classe et les classes créées sur son
modèle. Il s'agit de la même relation d'instanciation qu'il existe entre une
classe et ses objets (cette relation existe bien évidemment aussi entre une
méta-fonction et une fonction). A partir d'une méta-classe, comme pour une
méta-fonction, il est très simple d'instancier des classes pour manipuler
différents types d'objets. Il faut cependant bien faire la différence entre
l'instanciation d'un objet et l'instanciation d'une classe. La première consiste en
l'allocation physique d'une zone mémoire pour l'évolution d'un élément
dynamique du programme, alors que la seconde consiste en la création d'un nouveau type de
donnée qui est statique dans le programme (nous excluons de cette discussion les langages
qui permettent une manipulation dynamique des classes) et permettra par la suite d'instancier des
objets. L'exemple suivant crée des objets de classes instanciées à partir du
patron Liste<T>.
Liste<entier> * liste1 = new Liste<entier>();
Liste<Dessin> * liste2 = new Liste<Dessin>();
Liste<Noeud> * liste3;
L'expression Liste<Noeud> par exemple est seulement un moyen de
représenter un type de donnée, elle ne correspond en aucun cas à
l'exécution d'un quelconque code (hormis le fait que la variable liste3 est
créée), mais on parle pourtant d'instanciation, puisqu'elle donne de vrais types aux
paramètres du patron. Il y a tout de même une phase de création de la classe au
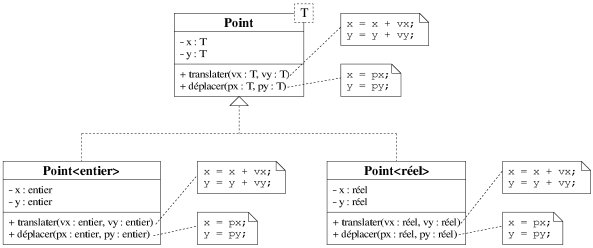
moment de la compilation. Lorsque le type Liste<Noeud> est rencontré pour
la première fois, le compilateur va instancier la classe, en dupliquant simplement le
modèle de la méta-classe et en remplaçant le paramètre T
par le type Dessin.
 |
| Figure 7.17: Un exemple de duplication de code lors de l'instanciation d'un patron. |
Le mécanisme d'instanciation d'une méta-classe (ou d'une méta-fonction) revient donc exactement à ce que le programmeur duplique une classe (ou une fonction) qu'il utilise pour un type donné et qu'il remplace manuellement ce type par un autre. Il n'y a donc aucun coût lié à l'utilisation d'un patron en terme de temps d'exécution, les mêmes optimisations que pour une recopie manuelle peuvent être effectuées. Au niveau de la taille du code, chaque instanciation d'un patron correspond à une duplication du code (cf. figure 7.17). Mais il faut savoir qu'actuellement des techniques d'instanciation permettent de factoriser le code dupliqué et réduisent significativement la taille du code généré (cf. [ORiordan02]). Heureusement, à quelques exceptions près (e.g. les systèmes embarqués), la taille du code d'un logiciel n'est plus critique à l'heure actuelle.
Il faut savoir également que, comme un patron est un modèle de composant, son implémentation ne peut pas être cachée, elle doit être connue du compilateur pour l'instanciation. Comme pour les méthodes inline, un patron se retrouve entièrement dans l'interface. Une modification de l'implémentation d'un patron entraîne nécessairement une recompilation de toutes ses instances. Ce qui peut conduire à des temps de compilation assez longs si les instances sont complexes et nombreuses (e.g. notre bibliothèque).
| 7.4.3. Polymorphisme statique, notion de concept |
L'intérêt principal du patron est que l'on développe un composant sans se soucier de la classe réelle de certaines données qu'il manipule, on suppose simplement qu'elles répondent à certains messages (i.e. que leur interface possède certaines propriétés) nécessaires pour la conception du composant. Ensuite, lorsque le réutilisateur veut exploiter le patron, il lui suffit de l'instancier en précisant les types des paramètres. Le composant est alors prêt à l'emploi, à condition que les paramètres possèdent les éléments d'interface requis. Cela fournit donc une forme de polymorphisme statique, puisqu'au moment où le patron est conçu, on fait appel à des méthodes sur des objets dont on ne connaît absolument pas le type, et c'est au moment de l'instanciation de la classe, i.e. à la compilation, que l'implémentation de la méthode pourra être déterminée.
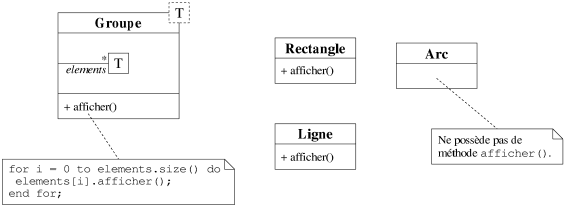 |
| Figure 7.18: Un exemple de polymorphisme statique avec un patron de classe. |
Pour préciser tout cela, considérons l'exemple de la figure 7.18. Une
méta-classe Groupe<T> représente un groupement d'objets et
possède une méthode afficher() qui appelle la méthode du
même nom pour tous les objets du groupe. L'instanciation de la méta-classe avec la
classe Ligne (ou la classe Rectangle) s'effectue sans difficulté.
Le compilateur, au moment où il écrit la méthode afficher() de la
classe Groupe<Ligne>, connaît le type des éléments du groupe
et peut donc identifier l'implémentation de la méthode afficher() de
Ligne. En revanche, s'il tente d'écrire la classe
Groupe<Arc>, il ne va pas trouver de méthode afficher() pour
la classe Arc et va donc échouer dans l'instanciation.
Il est alors possible de spécifier pour un patron les concepts (cf. [Austern99]) qu'une classe (ou un type de manière générale) doit modéliser pour être un candidat à l'instanciation de l'un de ses paramètres. Un concept est une fonctionnalité, i.e. un ensemble de propriétés dans l'interface, qu'une classe doit fournir. Un concept se traduit en programmation orientée objet par une interface qui est l'équivalent d'une classe possédant uniquement des signatures de méthodes dans sa partie publique. L'interface permet ainsi d'abstraire un service qu'une classe peut fournir. La relation d'héritage est naturellement possible entre interfaces.
Le formalisme UML et le langage Java permettent une distinction entre une classe et une
interface (cf. figure 7.19a). En revanche, dans le langage C++ une interface est simplement
représentée par une classe abstraite qui est une classe possédant
uniquement des signatures de méthodes, sans aucun corps (les plus avertis comprendront que
l'on assimile ici la classe abstraite au terme exact de classe abstraite pure). Une classe
non abstraite est dite concrète. Etant dépourvue de toute
implémentation, il est impossible d'instancier une classe abstraite. Le fait qu'une classe
fournisse une certaine interface est formalisé par une relation
d'implémentation. Par exemple, la figure 7.19a montre que la classe
Ligne implémente l'interface Affichable. En C++, cela se traduit
par le fait que la classe Ligne hérite de la classe abstraite
Affichable (cf. figure 7.19b).
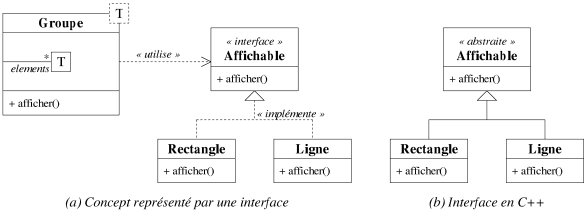 |
| Figure 7.19: Un exemple de concept. |
Il est donc possible de formaliser cette notion de concept en UML par la notion d'interface. Cependant, en C++ (Java n'implémentant pas les patrons), il n'est pas possible de spécifier directement qu'un patron n'accepte que certains concepts. Le moyen habituel pour prévenir le réutilisateur est de fournir une documentation détaillée du patron et des concepts qu'il supporte, e.g. le cadriciel STL (Standard Template Library [SGIWeb]). Mais si le réutilisateur tente une instanciation impossible, il est confronté à un message d'erreur dans un code qu'il n'a pas écrit (le message apparaît lorsque le compilateur tente d'écrire un envoi de message à une méthode qui n'existe pas, cf. [Siek00]). Un défaut majeur des patrons, du moins en C++, est qu'en cas de mauvaise utilisation, le message d'erreur retourné par le compilateur n'est compréhensible que par le créateur du patron. Nous parlons au dernier chapitre de techniques pour atténuer ce désagrément.
| 7.4.4. Réutilisabilité |
A première vue, le patron n'est pas un concept fondamental pour la
réutilisabilité. En effet, son unique intérêt est qu'il permet de
paramétrer un composant sur un ou plusieurs types de donnée, ce qui offre une bonne
abstraction des données manipulées par le composant. Mais l'héritage permet
lui aussi ce genre d'abstraction. Si l'on reprend l'exemple de la figure 7.18, il est possible de
créer une classe unique Groupe qui agrège des objets de la classe
abstraite Affichable spécialisée par les classes Ligne et
Rectangle (cf. figure 7.20). La même abstraction des objets
agrégés est alors fournie. Mais quel est donc le réel avantage du patron ?
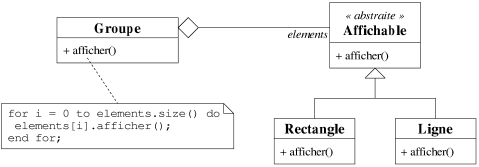 |
| Figure 7.20: Un autre exemple d'héritage. |
Principalement, il évite d'employer la virtualité, ce qui permet un gain significatif sur le temps d'exécution (surtout si des méthodes deviennent inline). En revanche, les types des données qu'il manipule étant fixés à l'instanciation, le patron est beaucoup moins flexible. Dans notre exemple, il ne permet de stocker que des éléments d'un même type. Certains diront que cela constitue un avantage (en effet, si l'on veut s'assurer que l'on a un groupe d'objets de la même classe), d'autres diront que c'est un défaut (en effet, si l'on veut traiter en une même commande un ensemble d'objets hétérogène). Choisir entre l'héritage et le patron dépend donc fortement de l'utilisation que l'on souhaite faire des composants. Dans un système dynamique, on choisira plutôt l'héritage alors que dans un système statique, on préférera le patron qui offre une efficacité bien meilleure.
Une différence notable au niveau conceptuel réside dans le fait que les objets
manipulés dans l'approche par héritage ont un lien de parenté, ils
héritent tous de la même super-classe Affichable alors que dans
l'approche par patron, aucun lien de parenté n'est présent, les objets doivent juste
implémenter (souvent implicitement) le concept Affichable. Cela permet pour
l'approche par patron de simplifier énormément la hiérarchie de
l'héritage et d'éviter des dépendances a priori inutiles entre les composants.
Mais cette différence conceptuelle a également un impact important sur la
réutilisabilité. En effet, un patron est totalement indépendant des types avec
lesquels il est instancié. Cela signifie que si l'on récupère une classe dont
on n'est pas l'auteur, mais qui implémente le concept nécessaire au patron, alors il
sera possible d'instancier le patron avec cette classe. Supposons la même chose avec
l'approche par héritage. Il est impossible de profiter de la classe Groupe pour
une classe dont on n'est pas l'auteur, puisqu'elle n'hérite pas de Affichable.
Deux solutions sont alors possibles: modifier la classe pour qu'elle hérite de
Affichable, mais il faut alors mesurer la portée du changement; ou utiliser la
délégation pour agréger la classe étrangère dans une nouvelle
classe héritant de Affichable.
Une autre différence conceptuelle du patron est qu'il manipule indifféremment les
classes et les types primitifs (e.g. entiers, réels). Ses paramètres sont simplement
des types qui doivent répondre à certains messages. L'avantage du patron, si l'on
reprend l'exemple de la figure 7.16, est que la classe Liste peut stocker aussi bien
des types primitifs que des classes (e.g. Dessin...), alors que la même classe
avec l'approche par héritage ne pourrait stocker que des objets d'une même classe de
base, et malheureusement la plupart des langages (e.g. Java et C++) ne considère pas les
types primitifs comme des classes.
Après réflexion, le patron s'avère être une manière toute particulière de réutiliser, avec une approche boîte noire et une abstraction sans distinction des types primitifs et des classes, il permet un découplage fort entre les composants. Contrairement à la composition, l'utilisation en boîte noire s'effectue sans aucun héritage, ce qui est un facteur indéniable d'efficacité. En revanche, le patron ne fournit qu'une structure statique et le polymorphisme dynamique fourni par l'héritage ou la délégation reste une nécessité pour beaucoup de systèmes.
| CONCLUSION |
La notion d'objet est un concept simple lié à notre perception de la plupart des systèmes réels. Cependant, tout au long de ce chapitre, nous avons découvert que concevoir une représentation orientée objet dans l'objectif d'une implémentation informatique s'avère être une tâche délicate. Les notions mises en oeuvre possèdent des nuances et des impacts sur l'implémentation dont on voudrait bien faire abstraction, mais ce faisant, cela pourrait conduire à un logiciel désastreux en termes de qualité et de réutilisabilité. Aux vues des problèmes introduits par les différents concepts de l'orientation objet, on s'aperçoit que pour des applications dites scientifiques où le temps d'exécution est critique, il est tout à fait impossible de faire abstraction des problématiques "bas niveau" que la programmation orientée objet induit. Ainsi, avec une bonne connaissance des mécanismes présentés dans ce chapitre, il est possible d'éviter les pièges classiques d'une modélisation orientée objet trop conceptuelle et d'aboutir à des composants tout à fait réutilisables et efficaces.
De l'orientation objet, nous pouvons retenir trois concepts majeurs permettant la réutilisabilité: l'héritage, la composition et le patron. Dans leurs apports à la réutilisabilité, il faut faire une distinction entre l'abstraction des composants qui se traduit par le polymorphisme, et l'extension d'un composant qui permet de lui ajouter de nouvelles fonctionnalités. L'héritage intervient au niveau de l'abstraction des composants, grâce à un polymorphisme coûteux, et au niveau de l'extensibilité, dont la mise en oeuvre est discutable à cause des risques latents de rupture d'encapsulation. La composition intervient au niveau de l'extension, par l'assemblage de composants. Enfin, le patron intervient au niveau de l'abstraction des composants, plus forte que celle de l'héritage, grâce à un polymorphisme sans aucun coût. L'abstraction fournie par l'héritage est dynamique alors que celle fournie par le patron est statique. L'extension fournie par l'héritage est statique alors que celle fournie par l'agrégation est dynamique. D'ailleurs, une combinaison judicieuse de l'héritage et de la composition produit le concept de délégation qui permet une abstraction dynamique et une extension dynamique.
Ainsi, en fonction du dynamisme et de l'efficacité que l'on souhaite pour un logiciel, on cherchera la meilleure combinaison des concepts d'héritage, de composition et de patron. Dans le cadre du développement d'une bibliothèque de composants réutilisables pour la recherche opérationnelle, il semble logique d'éviter le polymorphisme dynamique et de concentrer la conception plutôt sur le polymorphisme statique. Il est bien évident que cela n'exclut en aucun cas l'héritage de la conception. En évitant ce polymorphisme dynamique très coûteux, une approche dite programmation générique est apparue (cf. [Musser89]). Elle consiste à favoriser le concept de patron à la place de l'héritage dans la conception de composants génériques. Cette notion de généricité n'est pas limitée à la seule utilisation de patrons, mais à l'idée qu'un composant doit être le plus général possible sans que cela n'ait un impact négatif significatif sur son efficacité. Plusieurs travaux dont nous aurons l'occasion de discuter au chapitre suivant ont abouti dans ce sens.
Nous pouvons dès maintenant exclure le langage Java de nos possibilités, puisqu'il n'offre pas pour l'instant la notion de patron. C++ sera donc notre langage pour l'implémentation. Pour conclure, nous citons deux travaux élaborés avec ce langage et qui semblent tout à fait répondre aux critères de qualité, d'efficacité et de réutilisabilité. Ils offrent un espoir dans notre tentative de développer des composants réutilisables pour la recherche opérationnelle, à laquelle nous tentons d'apporter des éléments de réflexion au chapitre suivant.
Le premier travail est le désormais célèbre cadriciel STL (Standard Template Library [SGIWeb]) qui offre des structures de données et des algorithmes associés tout à fait efficaces et réutilisables. Le second travail est présenté dans [Haney99], il propose une classe représentant une abstraction des tableaux multidimensionnels. Les algorithmes manipulent cette classe sans connaître la représentation interne du tableau. Ils sont cependant très efficaces avec des performances similaires à celles d'une conception dédiée. Cet exemple est fort intéressant pour le calcul scientifique, puisqu'il règle le dilemme d'utiliser le langage Fortran avec sa représentation en colonne des tableaux, ou le langage C/C++ avec sa représentation en ligne.
|